The probable reasons you want to scrape LinkedIn Jobs are: –
- You want to create your own job data for a particular location
- Or do you want to analyze new trends in a particular domain and salaries?
However, in both cases, you have to either scrape LinkedIn Jobs data or use APIs of the platform (if they are cheap enough or available for public use).
In this tutorial, we will learn to extract data from LinkedIn & create our own LinkedIn Job Scraper, and since it does not provide any open API for us to access this data our only choice is to scrape it. We are going to use Python 3.x.

Also, if you are looking to scrape LinkedIn Jobs right away, we would recommend you use LinkedIn Jobs API by Scrapingdog. It is an API made to extract job data from this platform, the output you get is parsed JSON data.
Setting up the Prerequisites for LinkedIn Job Scraping
I am assuming that you have already installed Python 3.x on your machine. Create an empty folder that will keep our Python script and then create a Python file inside that folder.
mkdir jobs
After this, we have to install certain libraries which will be used in this tutorial. We need these libraries installed before even writing the first line of code.
Requests— It will help us make a GET request to the host website.BeautifulSoup— Using this library we will be able to parse crucial data.
Let’s install these libraries
pip install requests pip install beautifulsoup4
Analyze how LinkedIn job search works
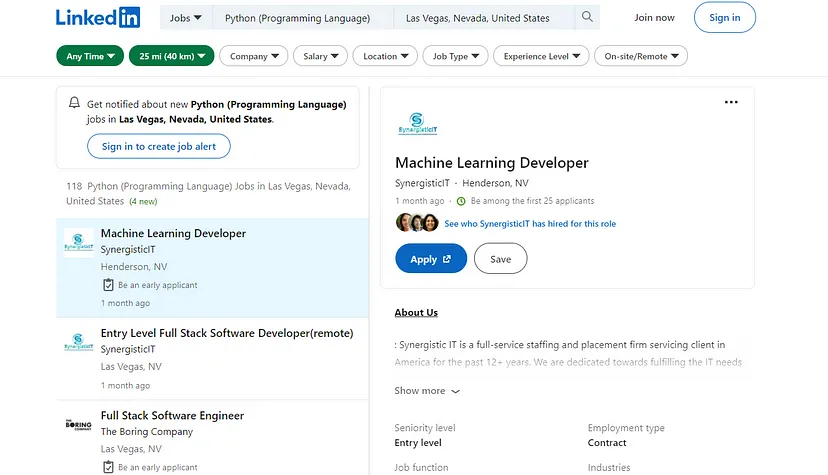
This is the page for Python jobs in Las Vegas. Now, if you will look at the URL of this page then it would look like this- https://www.linkedin.com/jobs/search?keywords=Python (Programming Language)&location=Las Vegas, Nevada, United States&geoId=100293800¤tJobId=3415227738&position=1&pageNum=0
Let me break it down for you.
keywords– Python (Programming Language)location– Las Vegas, Nevada, United StatesgeoId– 100293800currentJobId– 3415227738position– 1pageNum– 0
On this page, we have 118 jobs, but when I scroll down to the next page (this page has infinite scrolling) the pageNum does not change. So, the question is how can we scrape all the jobs?
The above problem can be solved by using a Selenium web driver. We can use .execute_script() method to scroll down the page and extract all the pages.
The second problem is how can we get data from the box on the right of the page. Every selected job will display other details like salary, duration, etc in this box.
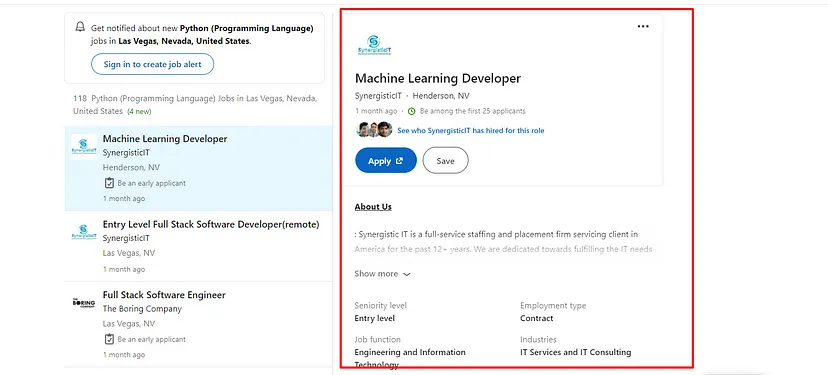
You can say that we can use .click() function provided by selenium. According to that logic, you will have to iterate over every listed job using a for loop and click on them to get details on the right box.
Yes, this method is correct but it is too time-consuming. Scrolling and clicking will put a load on our hardware which will prevent us from scraping at scale.
What if I told you that there is an easy way out from this problem and we can scrape LinkedIn in just a simple GET request?
Sounds unrealistic, right??
Finding the solution in the devtool
Let’s reload our target page with our dev tool open. Let’s see what appears in our network tab
We already know LinkedIn uses infinite scrolling to load the second page. Let’s scroll down to the second and see if something comes up in our network tab.
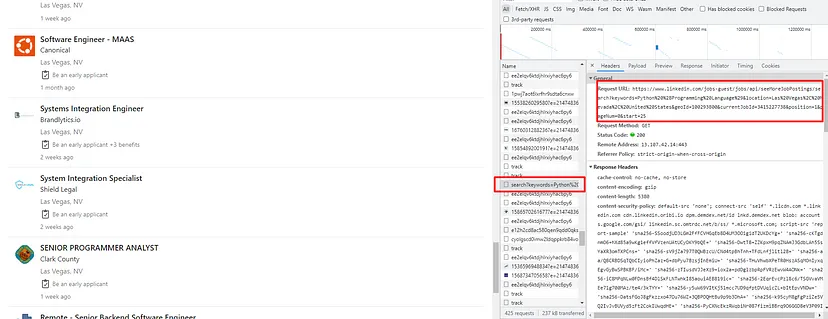
If you will click on the preview tab for the same URL then you will see all the job data.
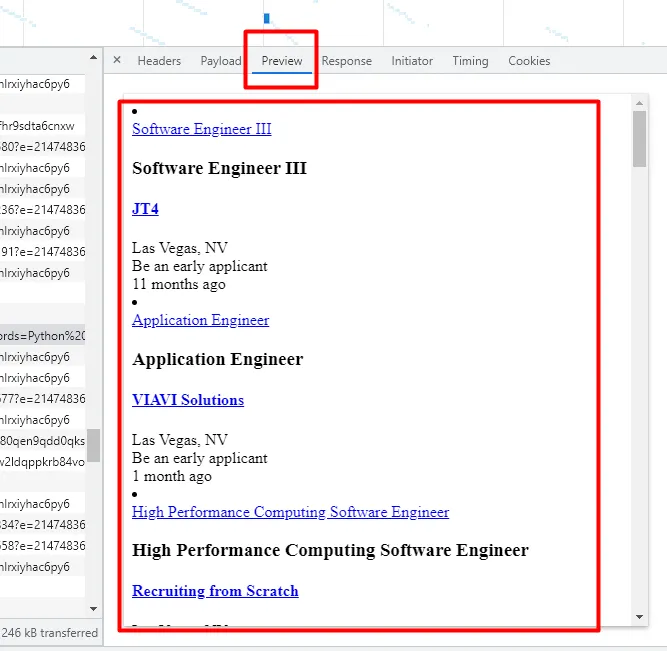
Let’s open this URL in our browser.

Ok, we can now make a small conclusion over here that every time when you scroll and LinkedIn loads another page, Linkedin will make a GET request to the above URL to load all the listed jobs.
Let’s break down the URL to better understand how it works.
https://www.linkedin.com/jobs-guest/jobs/api/seeMoreJobPostings/search?keywords=Python (Programming Language)&location=Las Vegas, Nevada, United States&geoId=100293800¤tJobId=3415227738&position=1&pageNum=0&start=25
keywords– Python (Programming Language)location– Las Vegas, Nevada, United StatesgeoId– 100293800currentJobId– 3415227738position– 1pageNum– 0start– 25
The only parameter that changes with the page is the start parameter. When you scroll down to the third page, the value of the start will become 50. So, the value of the start will increase by 25 for every new page. One more thing which you can notice is if you increase the value of start by 1 then the last job will get hidden.
Ok, now we have a solution to get all the listed jobs. What about the data that appears on the right when you click on any job? How to get that?
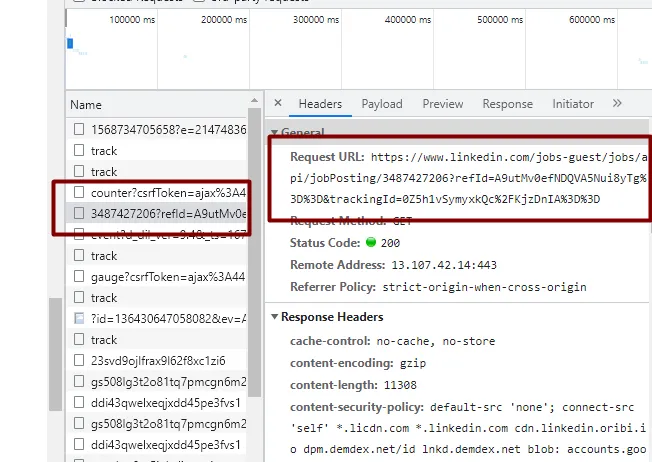
Whenever you click on a job, LinkedIn makes a GET request to this URL. But there is too much noise in the URL. The most simple form of the URL will look like this- https://www.linkedin.com/jobs-guest/jobs/api/jobPosting/3415227738
Here 3415227738 is the currentJobId which can be found in the li tag of every listed job.

Now, we have the solution to bypass selenium and make our scraper more reliable and scalable. We can now extract all this information with just a simple GET request using requests library.
What are we going to scrape?
It is always better to decide in advance what exact data points do you want to scrape from a page. For this tutorial, we are going to scrape three things.
- Name of the company
- Job position
- Seniority Level


Using .find_all() method of BeautifulSoup we are going to scrape all the jobs. Then we are going to extract jobids from each job. After that, we are going to extract job details from this API.
Scraping Linkedin Jobs IDs
Let’s first import all the libraries.
import requests from bs4 import BeautifulSoup
There are 117 jobs listed on this page for Python in Las Vegas.
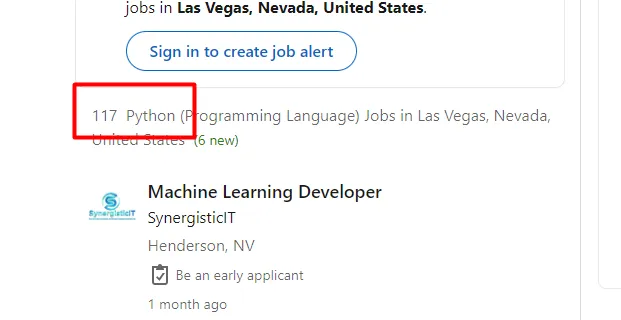
Since every page has 25 jobs listed, this is how our logic will help us scrape all the jobs.
- Divide 117 by 25
- If the value is a float number or a whole number we will use
math.ceil()method over it.
import requests
from bs4 import BeautifulSoup
import math
target_url='https://www.linkedin.com/jobs-guest/jobs/api/seeMoreJobPostings/search?keywords=Python%20%28Programming%20Language%29&location=Las%20Vegas%2C%20Nevada%2C%20United%20States&geoId=100293800¤tJobId=3415227738&start={}'
number_of_loops=math.ceil(117/25)
Let’s find the location of job IDs in the DOM.

The ID can be found under div tag with the class base-card. You have to find the data-entity-urn attribute inside this element to get the ID.
We have to use nested for loops to get the Job Ids of all the jobs. The first loop will change the page and the second loop will iterate over every job present on each page. I hope it is clear.
target_url='https://www.linkedin.com/jobs-guest/jobs/api/seeMoreJobPostings/search?keywords=Python%20%28Programming%20Language%29&location=Las%20Vegas%2C%20Nevada%2C%20United%20States&geoId=100293800¤tJobId=3415227738&start={}'
for i in range(0,math.ceil(117/25)):
res = requests.get(target_url.format(i))
soup=BeautifulSoup(res.text,'html.parser')
alljobs_on_this_page=soup.find_all("li")
for x in range(0,len(alljobs_on_this_page)):
jobid = alljobs_on_this_page[x].find("div",{"class":"base-card"}).get('data-entity-urn').split(":")[3]
l.append(jobid)
Here is the step-by-step explanation of the above code.
- we have declared a target URL where jobs are present.
- Then we are running a
for loopuntil the last page. - Then we made a
GETrequest to the page. - We are using
BS4for creating a parse tree constructor. - Using
.find_all()method we are finding all theli tagsas all the jobs are stored insideli tags. - Then we started another loop which will run until the last job is present on any page.
- We are finding the location of the
job ID. - We have pushed all the
IDsin an array.
In the end, array l will have all the ids for any location.
Scraping Job Details
Let’s find the location of the company name inside the DOM.

The name of the company is the value of the alt tag which can be found inside the div tag with class top-card-layout__card.

The job title can be found under the div tag with class top-card-layout__entity-info. The text is located inside the first a tag of this div tag.
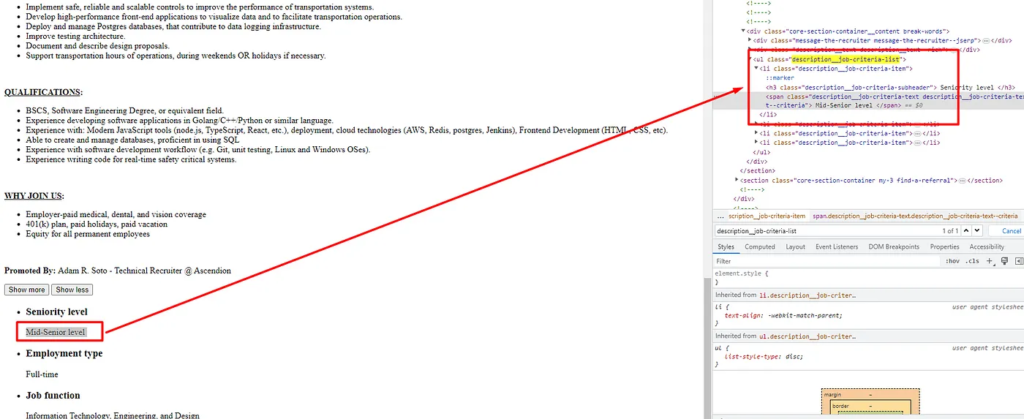
Seniority level can be found in the first li tag of ul tag with class description__job-criteria-list.
We will now make a GET request to the dedicated job page URL. This page will provide us with the information that we are aiming to extract from Linkedin. We will use the above DOM element locations inside BS4 to search for these respective elements.
target_url='https://www.linkedin.com/jobs-guest/jobs/api/jobPosting/{}'
for j in range(0,len(l)):
resp = requests.get(target_url.format(l[j]))
soup=BeautifulSoup(resp.text,'html.parser')
try:
o["company"]=soup.find("div",{"class":"top-card-layout__card"}).find("a").find("img").get('alt')
except:
o["company"]=None
try:
o["job-title"]=soup.find("div",{"class":"top-card-layout__entity-info"}).find("a").text.strip()
except:
o["job-title"]=None
try:
o["level"]=soup.find("ul",{"class":"description__job-criteria-list"}).find("li").text.replace("Seniority level","").strip()
except:
o["level"]=None
k.append(o)
o={}
print(k)
- We have declared a URL that holds the dedicated Linkedin job URL for any given company.
For loopwill run for the number of IDs present inside the array l.- Then we made a
GETrequest to the Linkedin page. - Again created a
BS4 parse tree. - Then we are using
try/exceptstatements to extract all the information. - We have pushed
object otoarray k. - Declared
object oempty so that it can store data of another URL. - In the end, we are printing the
array k.
After printing this is the result.
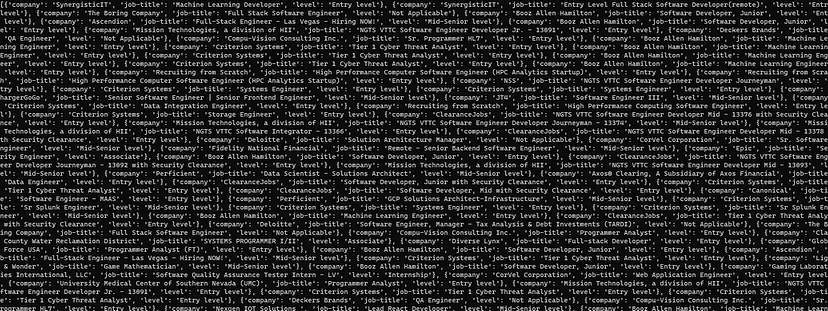
We have successfully managed to scrape the data from the Linkedin Jobs page. Let’s now save it to a CSV file now.
Saving the data to a CSV file
We are going to use the pandas library for this operation. In just two lines of code, we will be able to save our array to a CSV file.
How to install it?
pip install pandas
Import this library in our main Python file.
import pandas as pd
Now using DataFrame method we are going to convert our list kinto a row and column format. Then using .to_csv() method we are going to convert a DataFrame to a CSV file.
df = pd.DataFrame(k)
df.to_csv('linkedinjobs.csv', index=False, encoding='utf-8')
You can add these two lines once your list kis ready with all the data. Once the program is executed you will get a CSV file by the name linkedinjobs.csv in your root folder.
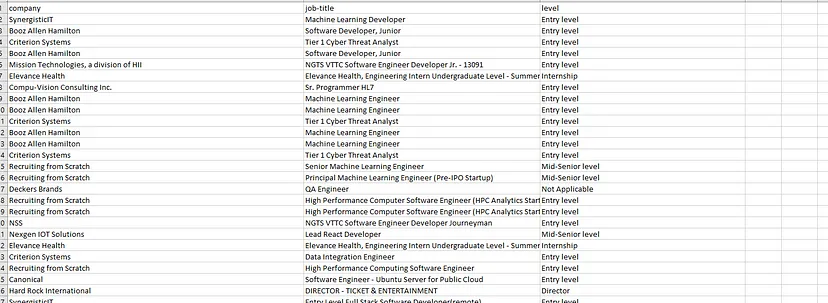
So, in just a few minutes we were able to scrape the Linkedin Jobs page and save it too in a CSV file. Now, of course, you can scrape many more other things like salary, location, etc. My motive was to explain to you how simple it is to scrape jobs from Linkedin without using resource-hungry Selenium.
Complete Code
Here is the complete code for scraping Linkedin Jobs.
import requests
from bs4 import BeautifulSoup
import math
import pandas as pd
l=[]
o={}
k=[]
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36"}
target_url='https://www.linkedin.com/jobs-guest/jobs/api/seeMoreJobPostings/search?keywords=Python%20%28Programming%20Language%29&location=Las%20Vegas%2C%20Nevada%2C%20United%20States&geoId=100293800¤tJobId=3415227738&start={}'
for i in range(0,math.ceil(117/25)):
res = requests.get(target_url.format(i))
soup=BeautifulSoup(res.text,'html.parser')
alljobs_on_this_page=soup.find_all("li")
print(len(alljobs_on_this_page))
for x in range(0,len(alljobs_on_this_page)):
jobid = alljobs_on_this_page[x].find("div",{"class":"base-card"}).get('data-entity-urn').split(":")[3]
l.append(jobid)
target_url='https://www.linkedin.com/jobs-guest/jobs/api/jobPosting/{}'
for j in range(0,len(l)):
resp = requests.get(target_url.format(l[j]))
soup=BeautifulSoup(resp.text,'html.parser')
try:
o["company"]=soup.find("div",{"class":"top-card-layout__card"}).find("a").find("img").get('alt')
except:
o["company"]=None
try:
o["job-title"]=soup.find("div",{"class":"top-card-layout__entity-info"}).find("a").text.strip()
except:
o["job-title"]=None
try:
o["level"]=soup.find("ul",{"class":"description__job-criteria-list"}).find("li").text.replace("Seniority level","").strip()
except:
o["level"]=None
k.append(o)
o={}
df = pd.DataFrame(k)
df.to_csv('linkedinjobs.csv', index=False, encoding='utf-8')
print(k)
Avoid getting blocked with Scrapingdog’s Linkedin Jobs API
You have to sign up for the free account to start using it. It will take just 10 seconds to get you started with Scrapingdog.
After successful registration, you will get your own API key from the dashboard.
import requests target_url='https://api.scrapingdog.com/linkedinjobs?api_key=Your-API-Key&field=Python%20(Programming%20Language)&geoid=100293800&page=1' resp = requests.get(target_url).json() print(resp)
With this API you will get parsed JSON data from the LinkedIn jobs page. All you have to do is pass the field which is the type of job you want to scrape, then geoid which is the location id provided by LinkedIn itself. You can find it in the URL of the LinkedIn jobs page and finally the page number. For each page number, you will get 25 jobs or less.
Once you run the above code you will get this result.
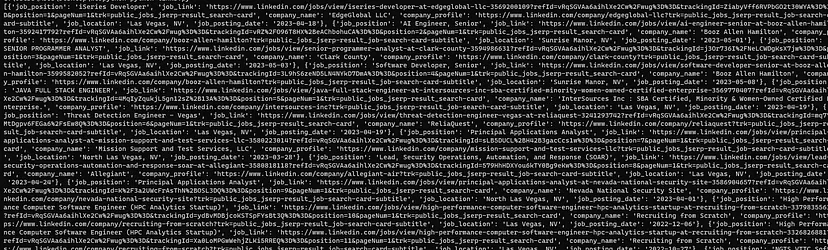
For a more detailed description of this API visit documentation or visit the LinkedIn Jobs API page.
Conclusion
In this post, we custom-created a LinkedIn Job scraper and were able to scrape LinkedIn job postings with just a normal GET request without using a scroll-and-click method. Using the pandas library we have saved the data in a CSV file too. Now, you can create your own logic to extract job data from many other locations. But the code will remain somewhat the same.
You can use lxml it in place of BS4 but I generally prefer BS4. But if you want to scrape millions of jobs then Linkedin will block you in no time. So, I would always advise you to use a Web Scraper API which can help you scrape this website without restrictions.
I hope you like this little tutorial and if you do then please do not forget to share it with your friends and on your social media.
What is the limit of LinkedIn web scraping?
With Scrapingdog, there is no limit to scraping LinkedIn. You can scrape 1 million job postings per day with our dedicated LinkedIn Jobs API.
Can LinkedIn ban you for scraping?
Yes, if detected by LinkedIn, it can ban you from scraping. Hitting the request from the same IP can get you under the radar and finally can block you. We have written an article describing what challenges you can face while scraping LinkedIn.
Additional Resources
Here are a few additional resources that you may find helpful during your web scraping journey:
- Web Scraping Indeed
- Web Scraping Glassdoor
- Best LinkedIn Scraping tools
- Scrape LinkedIn Profiles using Python
- Web Scraping LinkedIn Jobs to Airtable without Coding
- Web Scraping Amazon using Python
- Web Scraping Google Search Results using Python
Aside from these resources, you can find web scraping jobs here.
