Web scraping has become very crucial when it comes to data collection. No matter what kind of data you need you must have the skills to collect data from any target website. There are endless use cases of web scraping which makes it a “must-have” skill. You can use it to collect travel data or maybe product pricing from e-commerce websites like Amazon, etc.

We have written many articles on web scraping and have scraped various websites with Python but in this article, we will show you how it can be done with Nodejs.
This tutorial will be divided into two sections. In the first section we will scrape a website with a normal XHR request and then in the next section we will scrape another website that only loads data after Javascript execution.
But before we proceed with our setup for the scraper let’s first understand why you should prefer nodejs for building large scrapers.
Why Nodejs for Web Scraping?
The event loop in JavaScript is a critical component that enables Node.js to efficiently handle large-scale web scraping tasks. Javascript at any time can only do one thing as opposed to other languages like C or C++ that can have multiple threads to do multiple things at the same time.
An important distinction in Javascript where it can’t run things in parallel but it can run things concurrently. I know you are confused now. Things run at the same time but it process results at different times. Javascript cannot process all the functions at the same time.
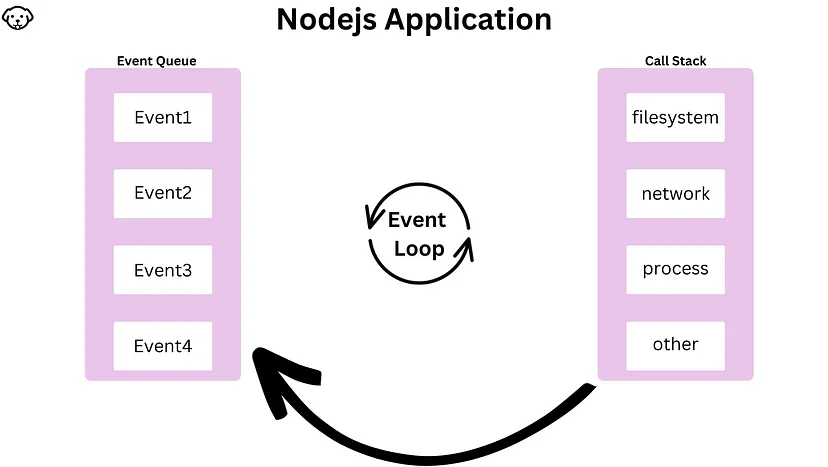
JavaScript, and consequently Node.js, is designed to be non-blocking and asynchronous. In a web scraping context, this means that Node.js can initiate tasks (such as making HTTP requests) and continue executing other code without waiting for those tasks to complete. This non-blocking nature allows Node.js to efficiently manage multiple operations concurrently.
Node.js uses an event-driven architecture. When an asynchronous operation, such as a network request or file read, is completed, it triggers an event. The event loop listens for these events and dispatches callback functions to handle them. This event-driven model ensures that Node.js can manage multiple tasks simultaneously without getting blocked.
With its event-driven and non-blocking architecture, Node.js can easily handle concurrency in web scraping. It can initiate multiple HTTP requests to different websites concurrently, manage the responses as they arrive, and process them as needed. This concurrency is essential for scraping large volumes of data efficiently.
How does Event Loop work?
- The event loop continuously checks if the call stack is empty.
- If the call stack is empty, the event loop checks the event queue for pending events.
- If there are events in the queue, the event loop dequeues an event and executes its associated callback function.
- The callback function may perform asynchronous tasks, such as reading a file or making a network request.
- When the asynchronous task is completed, its callback function is placed in the event queue.
- The event loop continues to process events from the queue as long as there are events waiting to be executed.
Setting up the prerequisites
I am assuming that you have already installed nodejs on your machine. If not then you can do so from here.
For this tutorial, we will mainly need three nodejs libraries.
Unirest– For making XHR requests to the website we are going to scrape.Cheerio– To parse the data we got by making the request throughunirest.Puppeteer– It is a nodejs library that will be used to control and automate headless Chrome or Chromium browsers. We will learn more about this later.
Before we install these libraries we will have to create a dedicated folder for our project.
mkdir nodejs_tutorial npm init
npm init will initialize a new Node.js Project. This command will create a package.json() file. Now, let’s install all of these libraries.
npm i unirest cheerio puppeteer
This step will install all the libraries in your project. Create a .js file inside this folder by any name you like. I am using first_section.js.
Now we are all set to create a web scraper. So, for the first section, we are going to scrape this page from books.toscrape.com.
Downloading raw data from books.toscrape.com
Our first job would be to make a GET request to our host website using unirest. Let’s test our setup first by making a GET request. If we get a response code of 200 then we can proceed ahead with parsing the data.
//first_section.js
const unirest = require('unirest');
const cheerio = require('cheerio');
async function scraper(){
let target_url = 'https://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html'
let data = await unirest.get(target_url)
return {status:data.status}
}
scraper().then((data) => {
console.log(data)
}).catch((err) => {
console.log(err)
})
Let me first explain this code to you step by step before running it.
Importing required modules:
- The
unirestmodule is imported to make HTTP requests and retrieve the HTML content of a web page. - The
cheeriomodule is imported to parse and manipulate the HTML content using jQuery-like syntax.
Defining the scraper async function:
- The
scraperfunction is an async function, which means it can use theawaitkeyword to pause execution and wait for promises to resolve. - Inside the function, a target URL (
https://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html) is assigned to thetarget_urlvariable.
Making an HTTP GET request and loading the HTML content:
- The
unirest.get()method is used to make an HTTP GET request to thetarget_url. - The
awaitkeyword is used to wait for the request to complete and retrieve the response object. - The HTML content of the response is accessed through
data.body.
Returning the result:
The scraper function returns an object with the status code of the HTTP response (data.status).
Invoking the scraper function:
- The
scraperfunction is called asynchronously usingscraper().then()syntax. - The resolved data from the function is logged into the console.
- Any errors that occur during execution are caught and logged into the console.
I hope you have got an idea of how this code is actually working. Now, let’s run this and see what status we get. You can run the code using the below command.
node first_section.js
When I run I get a 200 code.
{ status: 200 }
It means my code is ready and I can proceed ahead with the parsing process.
What are we going to scrape?
It is always great to decide this thing in advance what exact information you want to extract from the target page. This way we can analyze in advance which element is placed where inside the DOM.
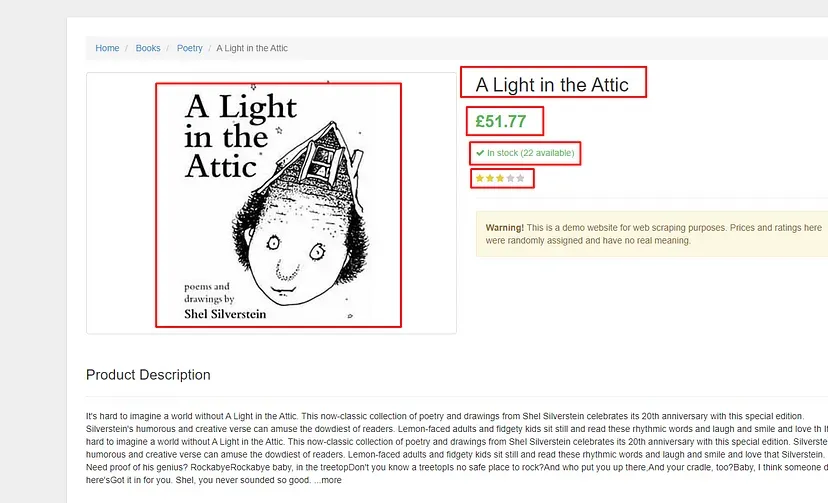
We are going to scrape five data elements from this page:
- Product Title
- Product Price
- In stock with quantity
- Product rating
- Product image.
We will start by making a GET request to this website with our HTTP agent unirest and once the data has been downloaded from the website we can use Cheerio to parse the required data.
With the help of .find() function of Cheerio, we are going to find each data and extract its text value.
Before making the request we are going to analyze the page and find the location of each element inside the DOM. One should always do this exercise to identify the location of each element.
We are going to do this by simply using the developer tool. This can be accessed by simply right-clicking on the target element and then clicking on the inspect. This is the most common method, you might already know this.
Identifying the location of each element
Let’s start by searching for the product title.
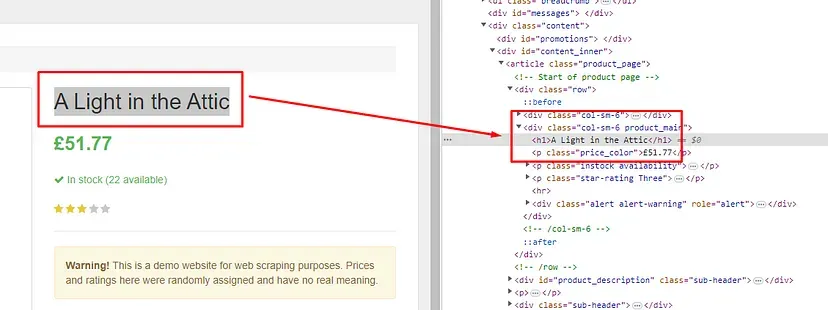
The title is stored inside h1 tag. So, this can be easily extracted using Cheerio.
const $ = cheerio.load(data.body);
obj["title"]=$('h1').text()
- The
cheerio.load()function is called, passing indata.bodyas the HTML content to be loaded. - This creates a Cheerio instance, conventionally assigned to the variable
$, which represents the loaded HTML and allows us to query and manipulate it using familiar jQuery-like syntax. - HTML structure has an
<h1>element, the code uses$('h1')to select all<h1>elements in the loaded HTML. But in our case, there is only one. .text()is then called on the selected elements to extract the text content of the first<h1>element found.- The extracted title is assigned to the
obj["title"]property.
Find the price of the product.
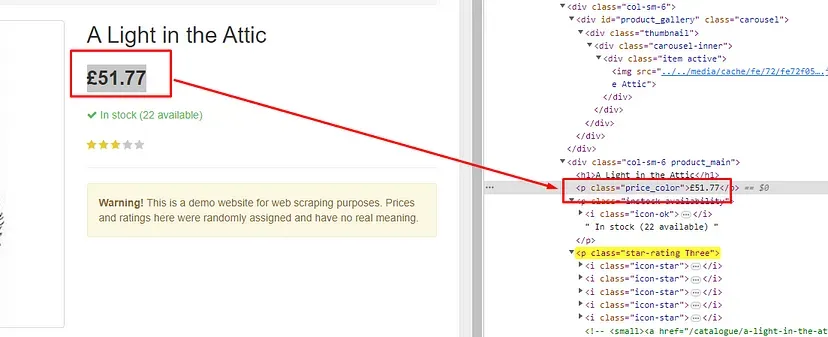
This price data can be found inside the p tag with class name price_color.
obj[“price_of_product”]=$(‘p.price_color’).text().trim()
Find the stock data
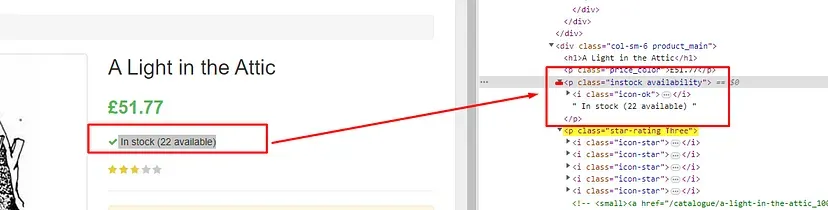
Stock data can be found inside p tag with the class name instock.
obj[“stock_data”]=$(‘p.instock’).text().trim()
Finding the star rating
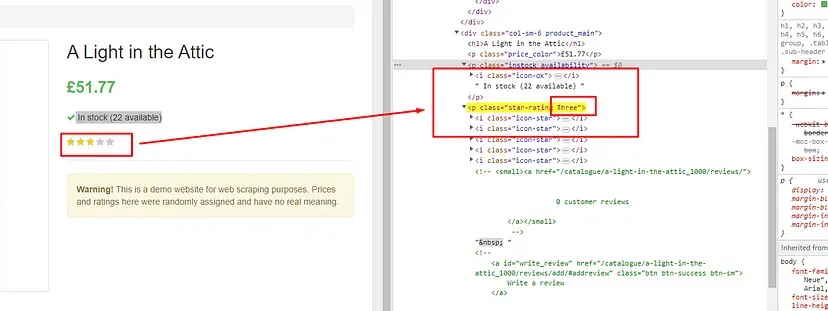
Here star rating is the name of the class. So, we will first find this class by the name star-rating and then we will find the value of this class attribute using .attr() function provided by the cheerio.
obj[“rating”]=$(‘p.star-rating’).attr(‘class’).split(“ “)[1]
Finding the image
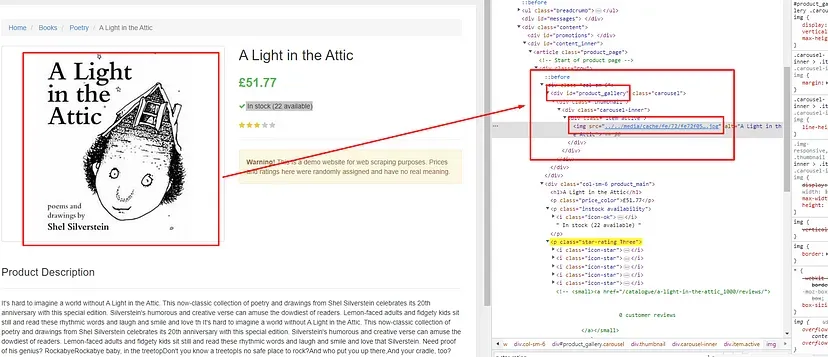
The image is stored inside an img tag which is located inside the div tag with id product_gallery.
obj[“image”]=”https://books.toscrape.com"+$('div#product_gallery').find('img').attr('src').replace("../..","")
By adding “https://books.toscrape.com” as a pretext we are completing the URL.
With this, we have managed to find every data we were planning to extract.
Complete Code
You can extract many other things from the page but my main motive was to show you how the combination of any HTTP agent(Unirest, Axios, etc) and Cheerio can make web scraping super simple.
The code will look like this.
const unirest = require('unirest');
const cheerio = require('cheerio');
async function scraper(){
let obj={}
let arr=[]
let target_url = 'https://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html'
let data = await unirest.get(target_url)
const $ = cheerio.load(data.body);
obj["title"]=$('h1').text()
obj["price_of_product"]=$('p.price_color').text().trim()
obj["stock_data"]=$('p.instock').text().trim()
obj["rating"]=$('p.star-rating').attr('class').split(" ")[1]
obj["image"]="https://books.toscrape.com"+$('div#product_gallery').find('img').attr('src').replace("../..","")
arr.push(obj)
return {status:data.status,data:arr}
}
scraper().then((data) => {
console.log(data.data)
}).catch((err) => {
console.log(err)
})
Read More: How to use a proxy with Axios and Nodejs
Scraping Websites with Headless Browsers in JavaScript
Why do we need a headless browser for scraping a website?
- Rendering JavaScript– Many modern websites rely heavily on JavaScript to load and display content dynamically. Traditional web scrapers may not execute JavaScript, resulting in incomplete or inaccurate data extraction. Headless browsers can fully render and execute JavaScript, ensuring that the scraped data reflects what a human user would see when visiting the site.
- Handling User Interactions– Some websites require user interactions, such as clicking buttons, filling out forms, or scrolling, to access the data of interest. Headless browsers can automate these interactions, enabling you to programmatically navigate and interact with web pages as needed.
- Captchas and Bot Detection– Many websites employ CAPTCHAs and anti-bot mechanisms to prevent automated scraping. Headless browsers can be used to solve CAPTCHAs and mimic human-like behavior, helping you bypass bot detection measures.
- Screenshots and PDF Generation– Headless browsers can capture screenshots or generate PDFs of web pages, which can be valuable for archiving or documenting web content.
Scraping website with Puppeteer
What is Puppeteer?
Puppeteer is a Node.js library developed by Google that provides a high-level API to control headless versions of the Chrome or Chromium web browsers. It is widely used for automating and interacting with web pages, making it a popular choice for web scraping, automated testing, browser automation, and other web-related tasks.
How does it work?
1. Installation:
- Start by installing Puppeteer in your Node.js project using npm or yarn.
- You can do this with the following command:
npm install puppeteer
2. Import Puppeteer:
- In your Node.js script, import the Puppeteer library by requiring it at the beginning of your script.
const puppeteer = require('puppeteer');
3. Launching a Headless Browser:
- Use Puppeteer’s
puppeteer.launch()method to start a headless Chrome or Chromium browser instance. - Headless means that the browser runs without a graphical user interface (GUI), making it more suitable for automated tasks.
- You can customize browser options during the launch, such as specifying the executable path or starting with a clean user profile.
4. Creating a New Page:
- After launching the browser, you can create a new page using the
browser.newPage()method. - This page object represents the tab or window in the browser where actions will be performed.
5. Navigating to a Web Page:
- Use the
page.goto()method to navigate to a specific URL. - Puppeteer will load the web page and wait for it to be fully loaded before proceeding.
6. Interacting with the Page:
- Puppeteer allows you to interact with the loaded web page, including:
- Clicking on elements.
- Typing text into input fields.
- Extracting data from the page’s DOM (Document Object Model).
- Taking screenshots.
- Generating PDFs.
- Evaluating JavaScript code on the page.
- These interactions can be scripted to perform a wide range of actions.
7. Handling Events:
- You can listen for various events on the page, such as network requests, responses, console messages, and more.
- This allows you to capture and handle events as needed during your automation.
8. Closing the Browser:
- When your tasks are complete, you should close the browser using
browser.close()to free up system resources. - Alternatively, you can keep the browser open for multiple operations if needed.
9. Error Handling:
- It’s important to implement error handling in your Puppeteer scripts to gracefully handle any unexpected issues.
- This includes handling exceptions, network errors, and timeouts.
I think this much information is enough for now on Puppeteer and I know you are eager to build a web scraper using Puppeteer. Let’s build a scraper.
Scraping Facebook with Nodejs and Puppeteer
We have selected Facebook because it loads its data through javascript execution. We are going to scrape this page using Puppeteer. The page looks like this.
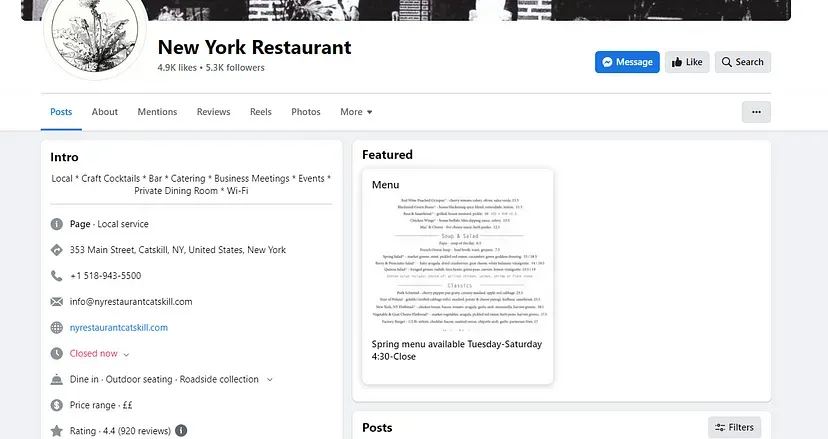
As usual, we should test our setup before starting with the scraping and parsing process.
Downloading the raw data from Facebook
We will write a code that will open the browser and then open the Facebook page that we want to scrape. Then it will close the browser once the page is loaded completely.
const puppeteer = require('puppeteer');
const cheerio = require('cheerio');
async function scraper(){
let obj={}
let arr=[]
let target_url = 'https://www.facebook.com/nyrestaurantcatskill/'
const browser = await puppeteer.launch({headless:false});
const page = await browser.newPage();
await page.setViewport({ width: 1280, height: 800 });
let crop = await page.goto(target_url, {waitUntil: 'domcontentloaded'});
let data = await page.content();
await page.waitFor(2000)
await browser.close();
return {status:crop.status(),data:data}
}
scraper().then((data) => {
console.log(data.data)
}).catch((err) => {
console.log(err)
})
This code snippet demonstrates an asynchronous function named scraper that uses Puppeteer for automating web browsers, to scrape data from a specific Facebook page.
Let’s break down the code step by step:
- The function
scraperis declared as an asynchronous function. It means that it can use theawaitkeyword to wait for asynchronous operations to complete. - Two variables,
objandarr, are initialized as empty objects and arrays, respectively. These variables are not used in the provided code snippet. - The
target_urlvariable holds the URL of the Facebook page you want to scrape. In this case, it is set to'https://www.facebook.com/nyrestaurantcatskill/'. puppeteer.launch({headless:false})launches a Puppeteer browser instance with theheadlessoption set tofalse. This means that the browser will have a visible UI when it opens. If you setheadlesstotrue, the browser will run in the background without a visible interface.browser.newPage()creates a new browser tab (page) and assigns it to thepagevariable.page.setViewport({ width: 1280, height: 800 })sets the viewport size of the page to 1280 pixels width and 800 pixels height. This simulates the screen size for the scraping operation.page.goto(target_url, {waitUntil: 'domcontentloaded'})navigates thepageto the specifiedtarget_url. The{waitUntil: 'domcontentloaded'}option makes the function wait until the DOM content of the page is fully loaded before proceeding.- The
cropvariable stores the result of thepage.gotooperation, which is a response object containing information about the page load status. page.content()retrieves the HTML content of the page as a string and assigns it to thedatavariable.page.waitFor(2000)pauses the execution of the script for 2000 milliseconds (2 seconds) before proceeding. This can be useful to wait for dynamic content or animations to load on the page.browser.close()closes the Puppeteer browser instance.- The function returns an object with two properties:
statusanddata. Thestatusproperty contains the status code of thecropresponse object, indicating whether the page load was successful or not. Thedataproperty holds the HTML content of the page.
Once you run this code you should see this.
If you see this then your setup is ready and we can proceed with data parsing using Cheerio.
What are we going to scrape?
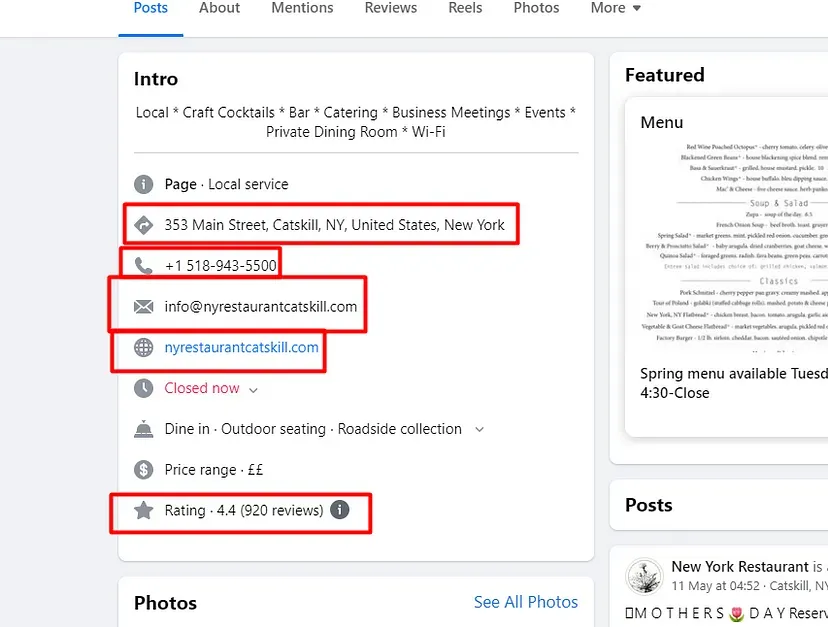
We are going to scrape these five data elements from the page.
- Address
- Phone number
- Email address
- Website
- Rating
Now as usual we are going to first analyze their location inside the DOM. We will take support of Chrome dev tools for this. Then using Cheerio we are going to parse each of them.
Identifying the location of each element
Let’s start with the address first and find out its location.
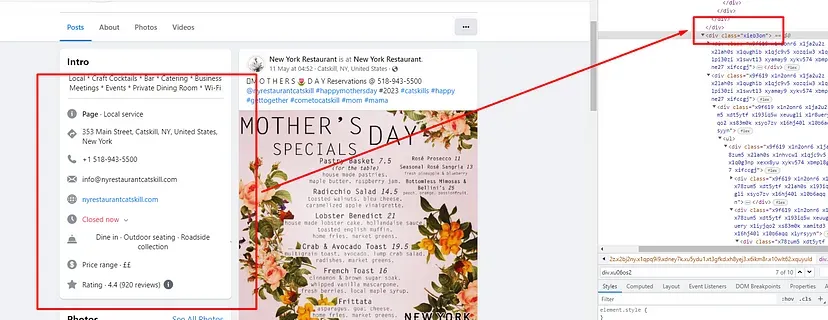
Once you inspect you will find that all the information we want to scrape is stored inside this div tag with the class name xieb3on. And then inside this div tag, we have two more div tags out of which we are interested in the second one because the information is inside that.
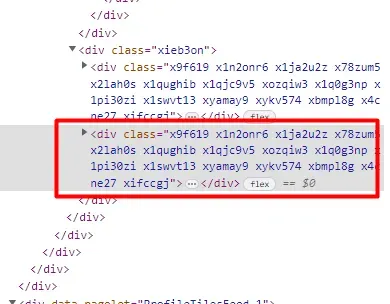
Let’s find this first.
$('div.xieb3on').first().find('div.x1swvt13').each((i,el) => {
if(i===1){
}
})
We have set a condition that only if i is 1 then only it will go inside the condition. With this, we have cleared our intention that we are only interested in the second div block. Now, the question is how to extract an address from this. Well, it become very easy now.
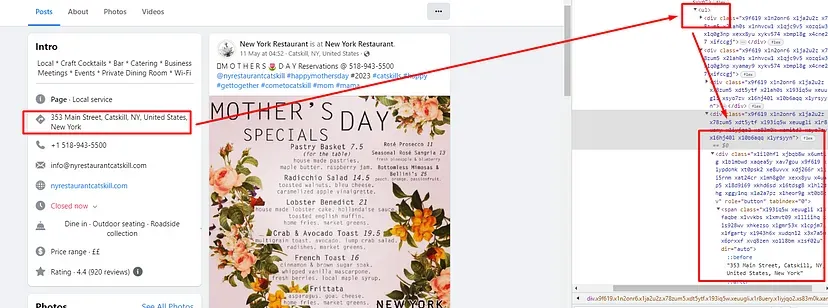
The address can be found inside the first div tag with the class x1heor9g. This div tag is inside the ul tag.
$('div.xieb3on').first().find('div.x1swvt13').each((i,el) => {
if(i===1){
obj["address"] = $(el).find('ul').find('div.x1heor9g').first().text().trim()
}
})
Let’s find the email, website, phone number, and the rating
All of these four elements are hidden inside div tags with classes xu06os2. All these four div tags are also inside the same ul tag as address.
$(el).find('ul').find('div.xu06os2').each((o,p) => {
let value = $(p).text().trim()
if(value.includes("+")){
obj["phone"]=value
}else if(value.includes("Rating")){
obj["rating"]=value
}else if(value.includes("@")){
obj["email"]=value
}else if(value.includes(".com")){
obj["website"]=value
}
})
arr.push(obj)
obj={}
.find('div.xu06os2')is used to find all<div>elements with the classxu06os2that are descendants of the previously selected<ul>elements..each((o,p) => { ... })iterates over each of the matched<div>elements, executing the provided callback function for each element.let value = $(p).text().trim()extracts the text content of the current<div>element (p) and trims any leading or trailing whitespace.- The subsequent
ifconditions check the extractedvaluefor specific patterns using the.includes()method:
a. If the value includes the “+” character, it is assumed to be a phone number, and it is assigned to the obj["phone"] property.
b. If the value includes the word “Rating”, it is assumed to be a rating value, and it is assigned to the obj["rating"] property.
c. If the value includes the “@” character, it is assumed to be an email address, and it is assigned to the obj["email"] property.
d. If the value includes the “.com” substring, it is assumed to be a website URL, and it is assigned to the obj["website"] property.
5. arr.push(obj) appends the current obj object to the arr array.
6. obj={} reassigns an empty object to the obj variable, resetting it for the next iteration.
Complete Code
Let’s see what the complete code looks like along with the response after running the code.
const puppeteer = require('puppeteer');
const cheerio = require('cheerio');
async function scraper(){
let obj={}
let arr=[]
let target_url = 'https://www.facebook.com/nyrestaurantcatskill/'
const browser = await puppeteer.launch({headless:false});
const page = await browser.newPage();
await page.setViewport({ width: 1280, height: 800 });
let crop = await page.goto(target_url, {waitUntil: 'domcontentloaded'});
await page.waitFor(5000)
let data = await page.content();
await browser.close();
const $ = cheerio.load(data)
$('div.xieb3on').first().find('div.x1swvt13').each((i,el) => {
if(i===1){
obj["address"] = $(el).find('ul').find('div.x1heor9g').first().text().trim()
$(el).find('ul').find('div.xu06os2').each((o,p) => {
let value = $(p).text().trim()
if(value.includes("+")){
obj["phone"]=value
}else if(value.includes("Rating")){
obj["rating"]=value
}else if(value.includes("@")){
obj["email"]=value
}else if(value.includes(".com")){
obj["website"]=value
}
})
arr.push(obj)
obj={}
}
})
return {status:crop.status(),data:arr}
}
scraper().then((data) => {
console.log(data.data)
}).catch((err) => {
console.log(err)
})
Let’s run it and see the response.
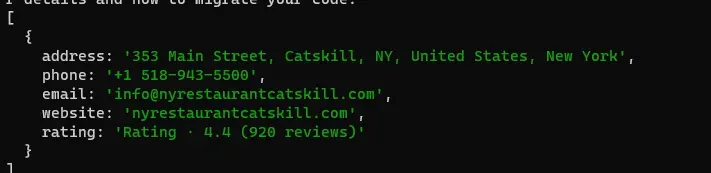
Well, finally we managed to scrape a dynamic website using JS rendering.
Scraping without getting blocked with Scrapingdog
Scrapingdog is a web scraping API that uses new proxy/IP on every new request. Once you start scraping Facebook at scale you will face two challenges.
- Puppeteer will consume too much CPU. Your machine will get super slow.
- Your IP will be banned in no time.
With Scrapingdog you can resolve both the issues very easily. It uses headless Chrome browsers to render websites and every request goes through a new IP.
const puppeteer = require('puppeteer');
const cheerio = require('cheerio');
async function scraper(){
let obj={}
let arr=[]
let target_url = 'https://www.facebook.com/nyrestaurantcatskill/'
const browser = await puppeteer.launch({headless:false});
const page = await browser.newPage();
await page.setViewport({ width: 1280, height: 800 });
let crop = await page.goto(target_url, {waitUntil: 'domcontentloaded'});
await page.waitFor(5000)
let data = await page.content();
await browser.close();
const $ = cheerio.load(data)
$('div.xieb3on').first().find('div.x1swvt13').each((i,el) => {
if(i===1){
obj["address"] = $(el).find('ul').find('div.x1heor9g').first().text().trim()
$(el).find('ul').find('div.xu06os2').each((o,p) => {
let value = $(p).text().trim()
if(value.includes("+")){
obj["phone"]=value
}else if(value.includes("Rating")){
obj["rating"]=value
}else if(value.includes("@")){
obj["email"]=value
}else if(value.includes(".com")){
obj["website"]=value
}
})
arr.push(obj)
obj={}
}
})
return {status:crop.status(),data:arr}
}
scraper().then((data) => {
console.log(data.data)
}).catch((err) => {
console.log(err)
})
As you can see you just have to make a simple GET request and your job is done. Scrapingdog will handle everything from headless chrome to retries for you.
If interested you can start with free 1000 credits to try how Scrapingdog can help you collect a tremendous amount of data.
Conclusion
Nodejs is a very powerful language for web scraping and this tutorial is evidence. Of course, you have to deep dive a little to better some basics but it is fast and robust.
In this tutorial, we learned how you can scrape both dynamic and non-dynamic websites with NodeJS. In the case of dynamic websites, you can also use playwright in place of the puppeteer.
I just wanted to give you an idea of how nodejs can be used for web scraping and I hope with this tutorial you will get a little clarity.
Additional Resources
And there’s the list! At this point, you should feel comfortable writing your first web scraper to gather data from any website. Here are a few additional resources that you may find helpful during your web scraping journey:
- Web Scraping with Node Unblocker
- Web Scraping with Ruby
- Web Scraping Python vs Nodejs
- Web Scraping with Python
- Web Scraping with cURL
- Web Scraping with Rust
- Web Scraping with Scrapy
- Web Scraping with Java
- Web Scraping with R
- Web Scraping with Go
- Web Scraping with C#
- Top 5 Javascript Web Scraping Libraries
- Puppeteer Web Scraping using JavaScript
