We need to install a few libraries before starting the project.
requestsfor making an HTTP connection with the target website.BeautifulSoupfor parsing the raw data.Pandasfor storing data in a CSV file.
For scraping this website, we are going to use Scrapingdog’s web scraping API, which will handle all the proxies, headless browsers, and captchas for me. You can sign up for the free pack to start with 1000 free credits.
The final step before coding would be to create a Python file where we will keep our Python code. I am naming the file as estate.py.
Before we start coding the scraper, take a moment to read Scrapingdog’s documentation; it’ll give you a clear idea of how we can use the API to scrape Homegate.ch at scale.
It’s always wise to determine exactly what information we want to extract from the target page before proceeding.
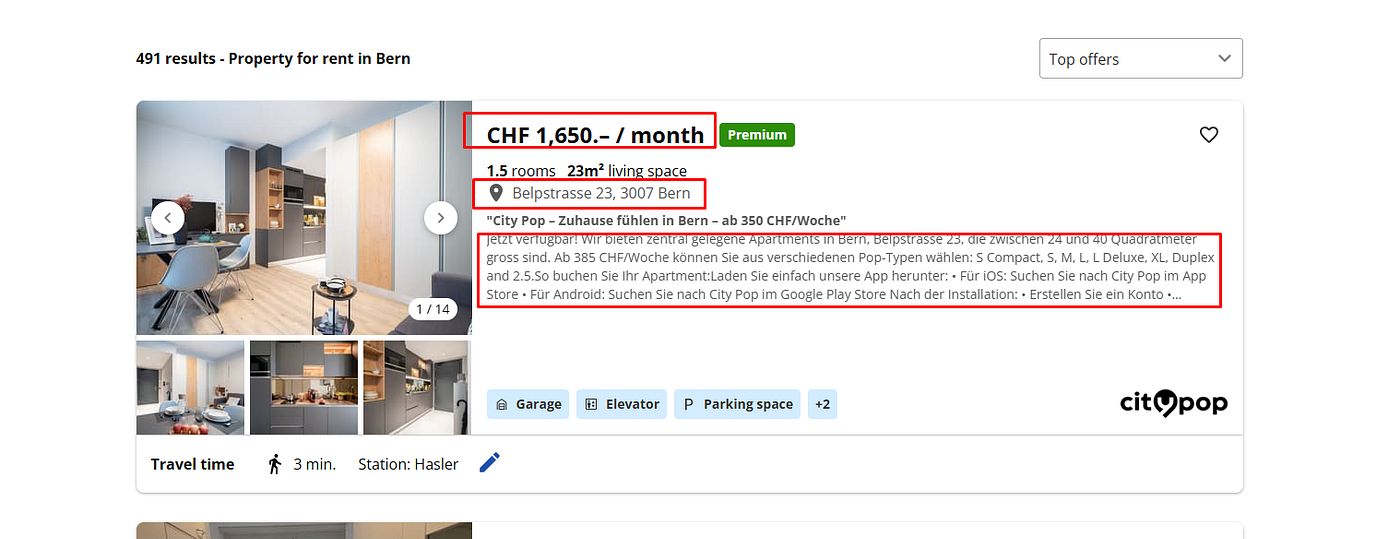
We are going to scrape:
- Price
- Address
- Description
Now, we have to find the location of each element inside the DOM.
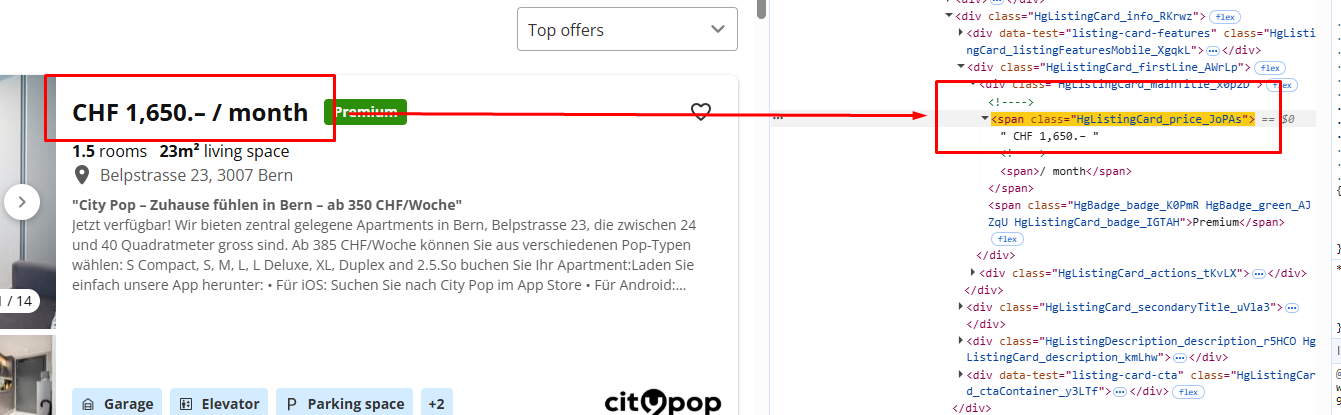
The price is stored inside the span tag with the class HgListingCard_price_JoPAs.
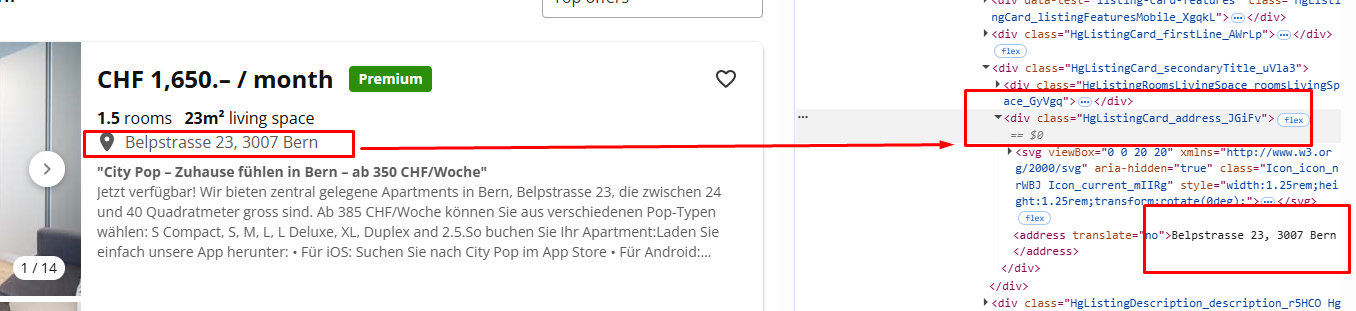
The address is stored inside a div tag with a class HgListingCard_address_JGiFv.
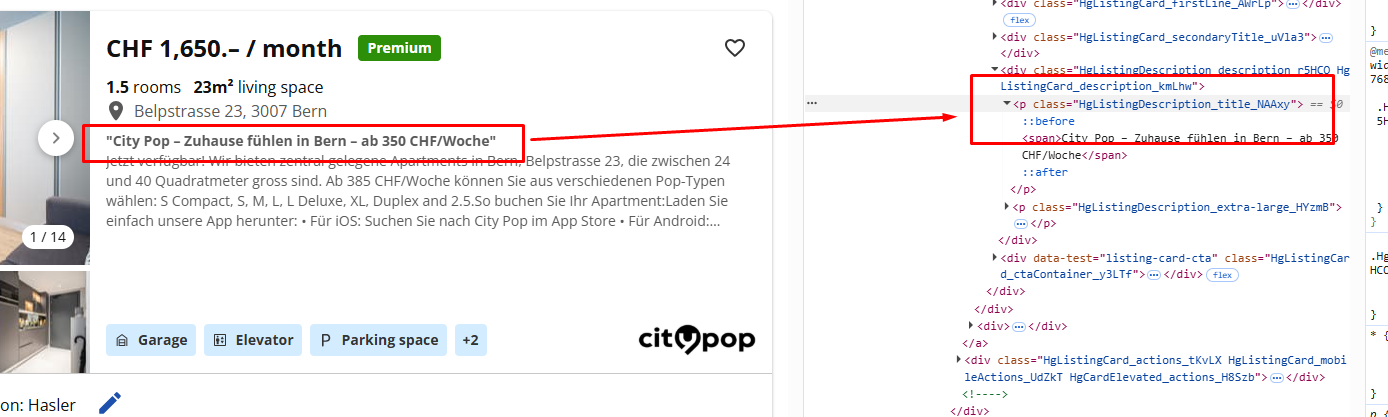
The description is stored inside a p tag with class HgListingDescription_title_NAAxy.
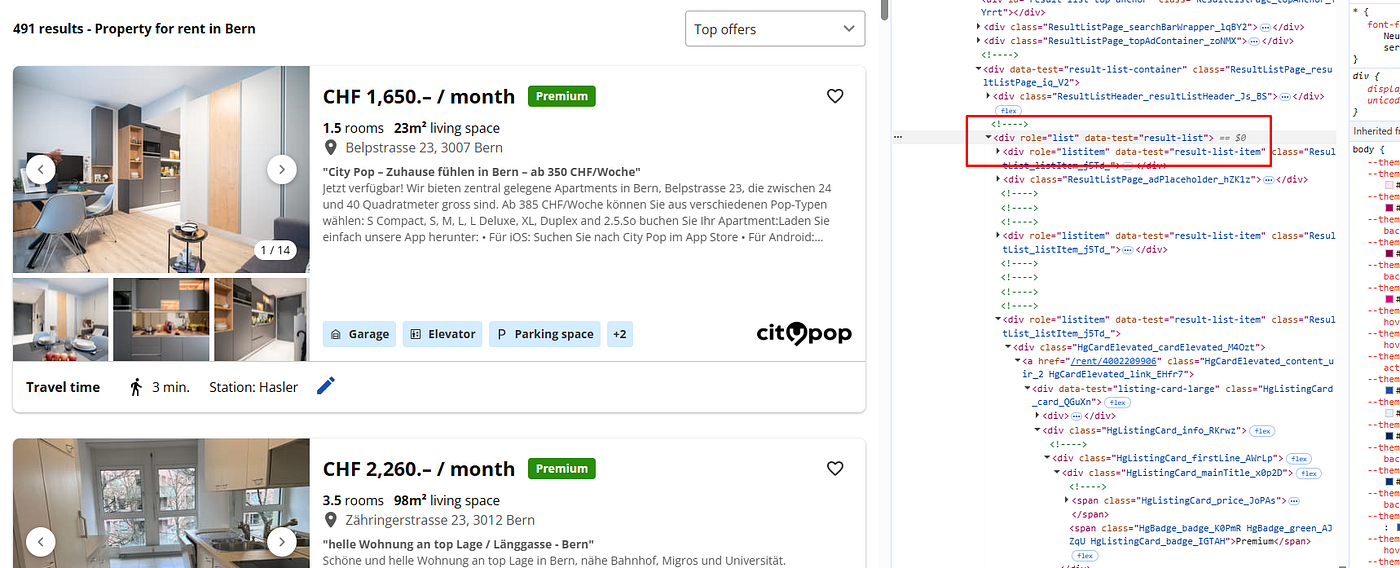
And all these properties are stored inside a div tag with the attribute data-test and value result-list-item.
The code is very simple, we are making a GET request to the host website using Scrapingdog’s API. Remember to use your own API key in the above code.
If we get a 200 status code, then we can proceed with the parsing process. Let’s run this code.
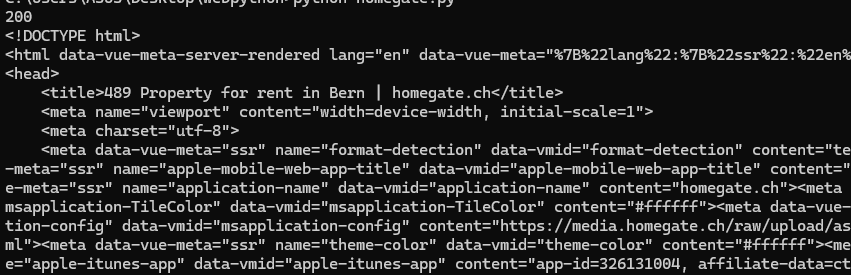
We got a 200 status code, and that means we have successfully scraped homegate.ch.
You will notice that when you click the second page, a new URL appears.
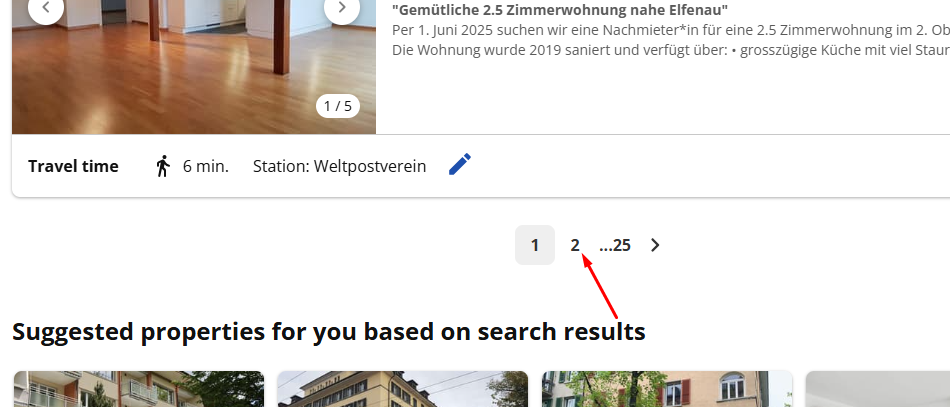
The URL of that page looks like https://www.homegate.ch/rent/real-estate/city-bern/matching-list?ep=2. So, that means the parameter ep is changing the page.
Now, to iterate over each page, we have to run another for loop to collect data from each page.
- Creates a DataFrame
dffrom the listl. - Saves the DataFrame to a CSV file named
homegate.csv. - Disables the index column in the CSV using
index=False.
Once you run it, you will find a CSV file by the name homegate.csv.
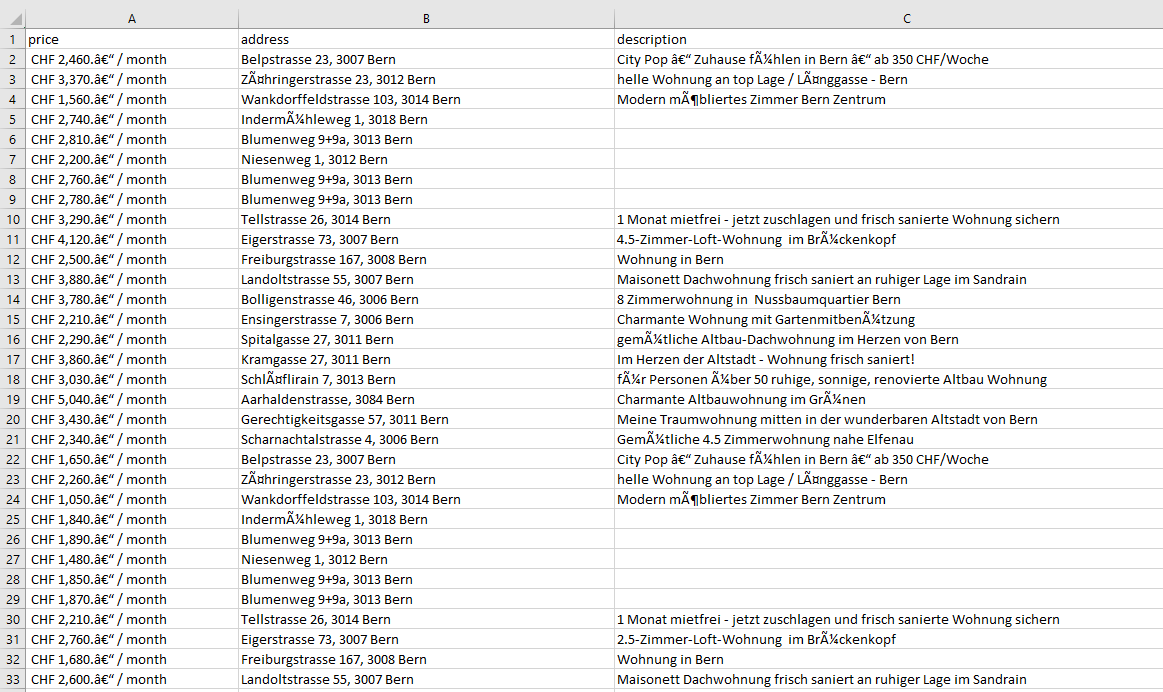
Now, in the above code, we created a parsing logic by finding the location of each element within the DOM. Now, this logic will fall flat if the website is redesigned again. To avoid this, you can use Scrapingdog’s AI query feature, where you just have to pass the prompt. Let me explain to you how.
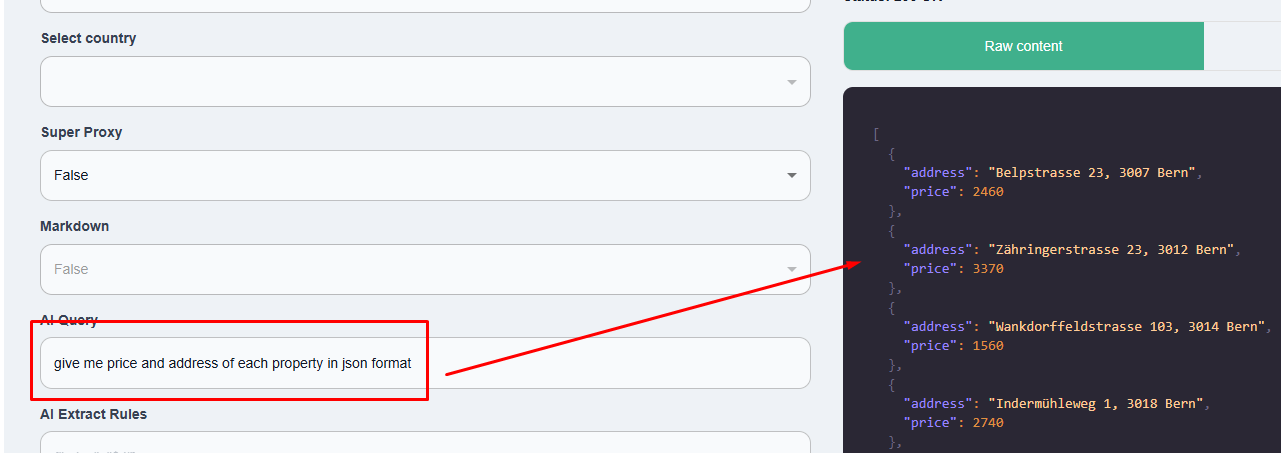
The code will look like this.