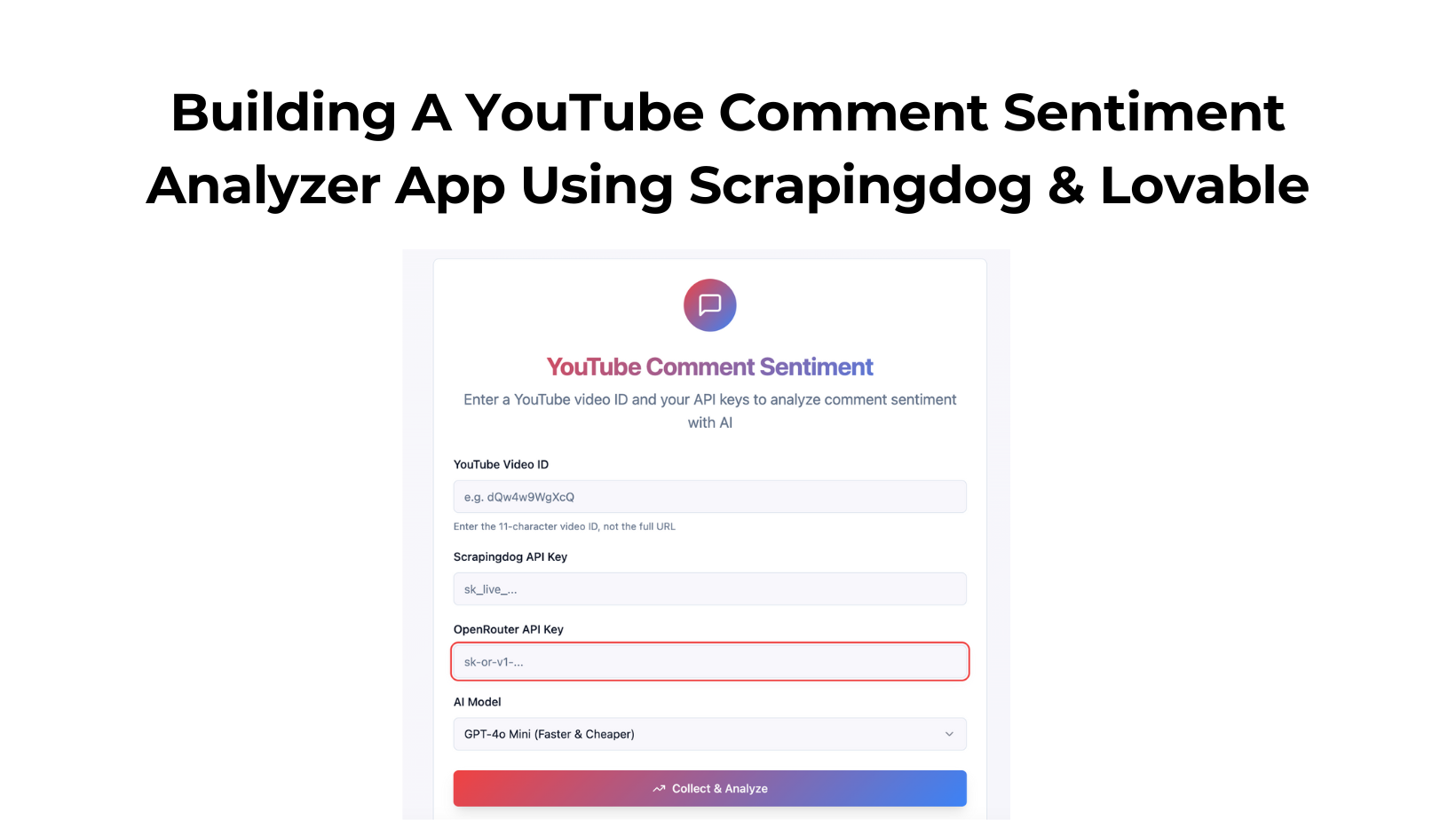
In this tutorial, we will build a simple app that performs sentiment analysis on all comments of a YouTube Video after aggregating them.
To build this app, we have used
- Scrapingdog’s YouTube Comments API (Get 1000 Free Credits for First Time SignUp)
- Lovable (Get 5 Free Credits Daily)
I have used ChatGPT to build the prompt, and here it is: –
Title: YouTube Comment Sentiment (1‑Paragraph Summary)
Goal:
Build a minimal Next.js app that:
Accepts a YouTube video ID (not the full URL) and two API keys entered on the frontend (Scrapingdog + OpenRouter).
Fetches all comments via Scrapingdog (10 per page with next_page_token).
Uses OpenRouter → OpenAI gpt‑4o / 4o‑mini to produce exactly one paragraph (≤120 words) summarizing overall sentiment.
No DB, no Supabase, no persistence; do not log keys.
Key UX:
Inputs: videoId, scrapingdogApiKey, openrouterApiKey, model (default openai/gpt-4o-mini, option openai/gpt-4o).
Button: Analyze Sentiment.
Show simple “Analyzing…” progress text while running.
Output: one paragraph only (no bullets, no tables, no per‑comment output).
Implementation:
Use Next.js App Router.
Frontend sends keys to backend per request; backend uses them only in memory.
Backend performs hierarchical summarization (chunk → mini summaries → final synthesis).
Basic backoff/retry, safe chunk size (~4000 chars).
Validate video ID (not URL).
Clamp final text to a single paragraph (≤120 words).
Create these files
1) app/page.tsx
tsx
Copy
Edit
"use client";
import { useState } from "react";
const YT_ID_RE = /^[A-Za-z0-9_-]{11}$/; // Standard YouTube ID length is 11
export default function Home() {
const [videoId, setVideoId] = useState("");
const [scrapingdogApiKey, setScrapingdogApiKey] = useState("");
const [openrouterApiKey, setOpenrouterApiKey] = useState("");
const [model, setModel] = useState("openai/gpt-4o-mini");
const [loading, setLoading] = useState(false);
const [summary, setSummary] = useState<string>("");
const [error, setError] = useState<string>("");
async function handleRun() {
setError("");
setSummary("");
if (!YT_ID_RE.test(videoId)) {
setError("Enter a valid YouTube video ID (11 characters, not a full URL).");
return;
}
if (!scrapingdogApiKey || !openrouterApiKey) {
setError("Both API keys are required.");
return;
}
setLoading(true);
try {
const res = await fetch("/api/run", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ videoId, scrapingdogApiKey, openrouterApiKey, model }),
});
const data = await res.json();
if (!res.ok) throw new Error(data?.error || "Failed");
setSummary(data.summaryParagraph || "");
} catch (e: any) {
setError(e?.message || "Something went wrong");
} finally {
setLoading(false);
}
}
return (
<main className="max-w-xl mx-auto p-6 space-y-4">
<h1 className="text-2xl font-semibold">YouTube Comment Sentiment</h1>
<p className="text-sm text-gray-600">
Enter the <b>video ID</b> (not the full URL), add your API keys, and get a single-paragraph sentiment summary.
</p>
<label className="block">
<span className="text-sm">YouTube Video ID</span>
<input
className="w-full border rounded p-2"
placeholder="e.g. dQw4w9WgXcQ"
value={videoId}
onChange={(e) => setVideoId(e.target.value.trim())}
/>
</label>
<label className="block">
<span className="text-sm">Scrapingdog API Key</span>
<input
className="w-full border rounded p-2"
placeholder="sk_live_..."
value={scrapingdogApiKey}
onChange={(e) => setScrapingdogApiKey(e.target.value)}
type="password"
/>
</label>
<label className="block">
<span className="text-sm">OpenRouter API Key</span>
<input
className="w-full border rounded p-2"
placeholder="sk-or-v1-..."
value={openrouterApiKey}
onChange={(e) => setOpenrouterApiKey(e.target.value)}
type="password"
/>
</label>
<label className="block">
<span className="text-sm">Model</span>
<select
className="w-full border rounded p-2"
value={model}
onChange={(e) => setModel(e.target.value)}
>
<option value="openai/gpt-4o-mini">openai/gpt-4o-mini (cheaper)</option>
<option value="openai/gpt-4o">openai/gpt-4o</option>
</select>
</label>
<button
onClick={handleRun}
disabled={loading}
className="w-full rounded bg-black text-white py-2 disabled:opacity-60"
>
{loading ? "Analyzing…" : "Analyze Sentiment"}
</button>
{error && <p className="text-red-600 text-sm">{error}</p>}
{summary && (
<div className="border rounded p-3 bg-gray-50">
<p className="text-sm leading-6">{summary}</p>
</div>
)}
</main>
);
}
2) app/api/run/route.ts
ts
Copy
Edit
import { NextRequest, NextResponse } from "next/server";
export const dynamic = "force-dynamic";
type Comment = { id: string; text: string; author?: string; published_at?: string };
const OPENROUTER_BASE = "https://openrouter.ai/api/v1";
const DEFAULT_MODEL = "openai/gpt-4o-mini"; // switch to "openai/gpt-4o" via UI if desired
const YT_ID_RE = /^[A-Za-z0-9_-]{11}$/; // require ID not URL
// 1) Fetch ALL comments via Scrapingdog (10 per page) using next_page_token
async function fetchAllComments(
videoId: string,
scrapingdogApiKey: string
): Promise<Comment[]> {
const base = "https://api.scrapingdog.com/youtube/comments";
let token: string | undefined = undefined;
const out: Comment[] = [];
// Page through until next token is exhausted
while (true) {
const params = new URLSearchParams({ api_key: scrapingdogApiKey, video_id: videoId });
if (token) params.set("next_page_token", token);
const url = `${base}?${params.toString()}`;
const res = await fetch(url, { method: "GET", cache: "no-store" });
if (!res.ok) {
const txt = await res.text().catch(() => "");
throw new Error(`Scrapingdog ${res.status}: ${txt || res.statusText}`);
}
const data = await res.json();
const items: any[] = data?.comments || [];
for (const c of items) {
const id = c?.comment_id ?? c?.id;
const text = c?.text_original ?? c?.text ?? "";
if (!id || !text) continue;
out.push({
id: String(id),
text: String(text),
author: c?.author_display_name,
published_at: c?.published_at,
});
}
token = data?.scrapingdog_pagination?.next ?? data?.next_page_token ?? undefined;
// gentle pacing
await new Promise((r) => setTimeout(r, 120));
if (!token) break;
}
// Deduplicate by comment_id
return Array.from(new Map(out.map((c) => [c.id, c])).values());
}
// 2) OpenRouter helper
async function callOpenRouter({
apiKey,
model,
system,
user,
temperature = 0,
}: {
apiKey: string;
model: string;
system: string;
user: string;
temperature?: number;
}): Promise<string> {
const res = await fetch(`${OPENROUTER_BASE}/chat/completions`, {
method: "POST",
headers: {
Authorization: `Bearer ${apiKey}`,
"Content-Type": "application/json",
"HTTP-Referer": "https://yourapp.local", // attribution (any string)
"X-Title": "YouTube Sentiment",
},
body: JSON.stringify({
model,
temperature,
messages: [
{ role: "system", content: system },
{ role: "user", content: user },
],
}),
});
if (!res.ok) {
const txt = await res.text().catch(() => "");
throw new Error(`OpenRouter ${res.status}: ${txt || res.statusText}`);
}
const json = await res.json();
return json?.choices?.[0]?.message?.content?.trim() || "";
}
// 3) Chunk comments and summarize (hierarchical)
function chunkCommentsByChars(comments: Comment[], maxChars = 4000): string[] {
const chunks: string[] = [];
let buf = "";
for (const c of comments) {
const line = (c.text || "").replace(/\s+/g, " ").trim();
if (!line) continue;
if ((buf.length + line.length + 4) > maxChars) {
if (buf) chunks.push(buf);
buf = line;
} else {
buf = buf ? `${buf}\n---\n${line}` : line;
}
}
if (buf) chunks.push(buf);
return chunks;
}
const CHUNK_SYSTEM = `You are a precise sentiment summarizer. Output plain text only. No lists, no headings, no JSON.`;
const CHUNK_USER_TEMPLATE = (commentsPlain: string) => `
You will see a batch of YouTube comments (raw text).
Write a concise 2–3 sentence summary of the sentiment and main themes in neutral, professional tone.
Handle slang, emojis, sarcasm, and mixed opinions.
Output plain text only. No bullets, no labels, no JSON.
Comments:
${commentsPlain}
`.trim();
const FINAL_SYSTEM = `You are a precise sentiment summarizer. Output exactly one paragraph (<=120 words). No lists, no headings, no JSON.`;
const FINAL_USER_TEMPLATE = (miniSummaries: string[]) => `
You will see multiple short summaries, each representing a subset of YouTube comments from the same video.
Synthesize them into EXACTLY ONE PARAGRAPH (<=120 words) that states the overall sentiment (positive, neutral, or negative), briefly explains why, and notes any prominent themes or controversies.
Consider sarcasm, emojis, and mixed opinions.
Output one paragraph only. No bullets, no titles, no JSON.
Batch Summaries:
${miniSummaries.join("\n")}
`.trim();
export async function POST(req: NextRequest) {
try {
const { videoId, scrapingdogApiKey, openrouterApiKey, model } = await req.json();
// Validate inputs
if (!videoId || !YT_ID_RE.test(videoId)) {
return NextResponse.json({ error: "Please provide a valid YouTube video ID (11 chars, not a full URL)." }, { status: 400 });
}
if (!scrapingdogApiKey) {
return NextResponse.json({ error: "scrapingdogApiKey is required." }, { status: 400 });
}
if (!openrouterApiKey) {
return NextResponse.json({ error: "openrouterApiKey is required." }, { status: 400 });
}
const modelToUse = (model && typeof model === "string") ? model : DEFAULT_MODEL;
// 1) Collect all comments
const comments = await fetchAllComments(videoId, scrapingdogApiKey);
if (!comments.length) {
return NextResponse.json({
summaryParagraph: "No comments were found for this video, so there is no sentiment to summarize."
});
}
// 2) Chunk -> mini summaries
const chunks = chunkCommentsByChars(comments, 4000);
const miniSummaries: string[] = [];
for (const chunk of chunks) {
try {
const mini = await callOpenRouter({
apiKey: openrouterApiKey,
model: modelToUse,
system: CHUNK_SYSTEM,
user: CHUNK_USER_TEMPLATE(chunk),
temperature: 0,
});
if (mini) miniSummaries.push(mini);
await new Promise((r) => setTimeout(r, 200)); // gentle pacing
} catch {
// one retry
const mini = await callOpenRouter({
apiKey: openrouterApiKey,
model: modelToUse,
system: CHUNK_SYSTEM,
user: CHUNK_USER_TEMPLATE(chunk),
temperature: 0,
});
if (mini) miniSummaries.push(mini);
}
}
// 3) Final synthesis -> EXACTLY one paragraph (<=120 words)
const finalParagraph = await callOpenRouter({
apiKey: openrouterApiKey,
model: modelToUse,
system: FINAL_SYSTEM,
user: FINAL_USER_TEMPLATE(miniSummaries),
temperature: 0,
});
// Ensure one paragraph, clamp length
const oneLine = finalParagraph.replace(/\n+/g, " ").trim();
const words = oneLine.split(/\s+/);
const clamped = words.length <= 130 ? oneLine : words.slice(0, 120).join(" ") + "…";
return NextResponse.json({ summaryParagraph: clamped });
} catch (err: any) {
return NextResponse.json({ error: err?.message || "Unexpected error" }, { status: 500 });
}
}
Notes & Next Steps
No DB: Keys are provided by the user each run; nothing is stored.
The output you will get would be something similar to this: –
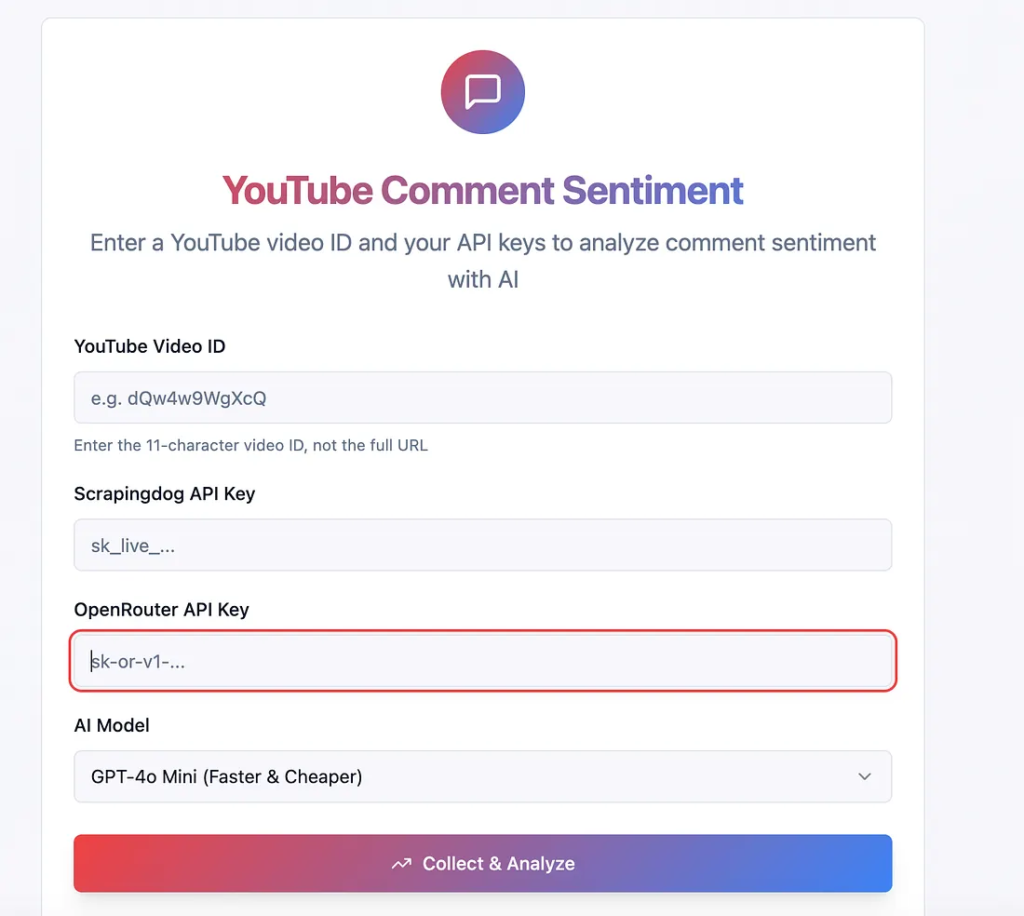
Here is the public link that you can use to test our setup.
OpenRouter is essentially the same as ChatGPT, but it is an aggregator of AI models, including ChatGPT, and in this way, I have access to all LLM models from a single dashboard.
Let’s start building this App!! Here is a quick walkthrough video of this tutorial.
If you would like to read text & build this from scratch, read along.
After successfully signing up on Lovable, you need to paste the prompt that I just gave to it.
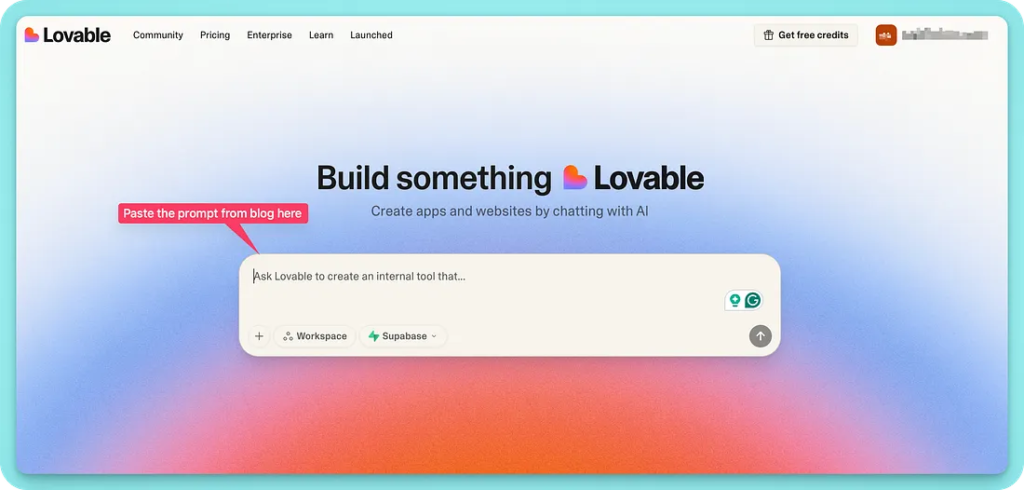
The tool will take some time and prepare a unique link for your tool.
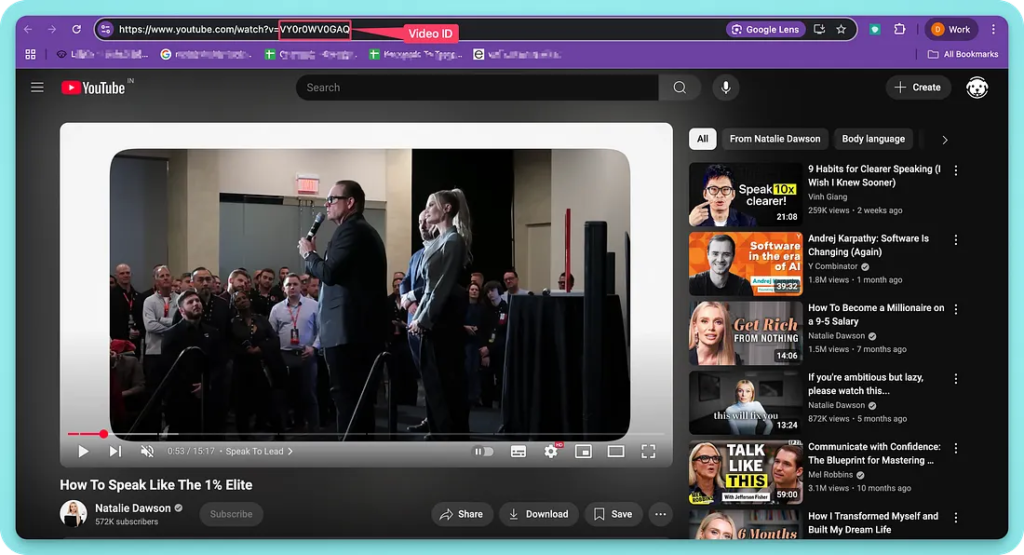
From there on, you would need a video ID, the Scrapingdog’s & OpenRouter’s API Key.
A video ID is part of the YouTube URL that is unique to every video. And this is one of the parameters that is used by the YouTube comment API.
You can find your Scrapingdog’s unique key on the dashboard.
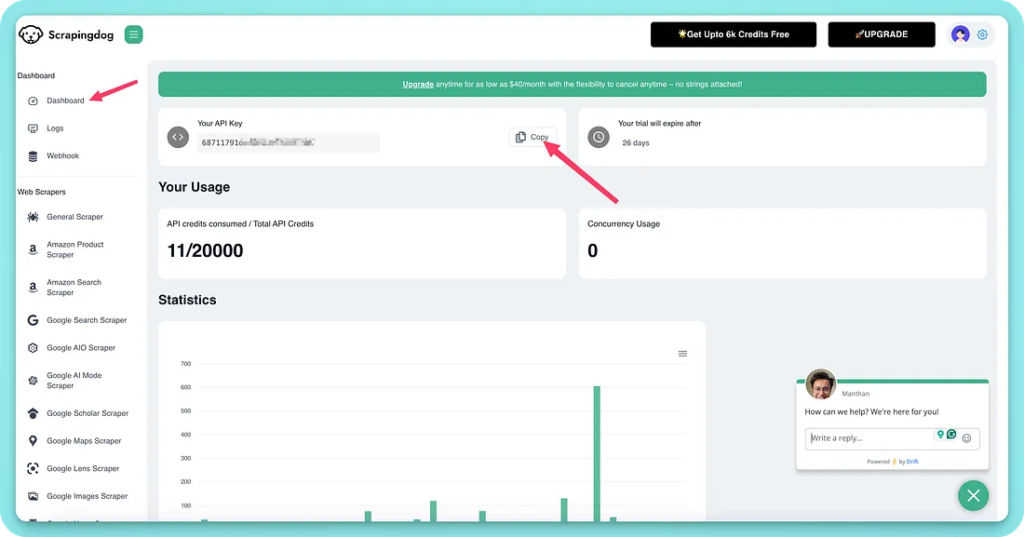
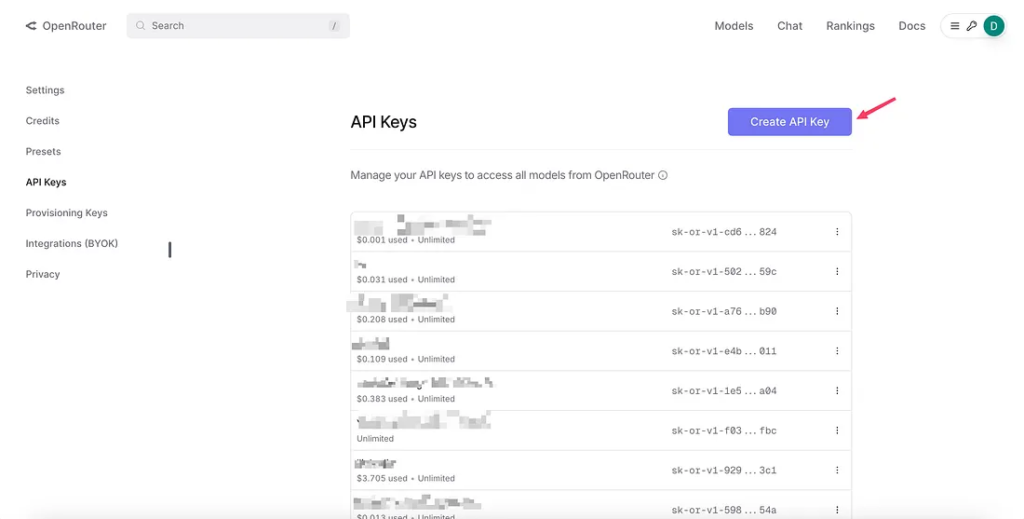
And finally, the OpenRouter Key, once you have an account on it, you need to top it up with some real money to get credits. Create a unique key from their dashboard.
Alright, here’s how the tool would work when you have all the parameters filled in there.
And this way, you can use Scrapingdog’s YouTube Comment API in this specific use case. We do have more dedicated endpoints for YouTube & Google APIs.
Additional Resources
- How You Can Extract YouTube Videos’ Transcripts For Free
- How To Scrape YouTube Transcript using Python
- Building A Google AI Mode Tracker using Scrapingdog & Lovable
- Scraping YouTube Comments using Python & OpenAI for Sentiment Analysis
- Finding the Right YouTube Influencers using Scrapingdog’s Google SERP API & YouTube Channel Scraper


