
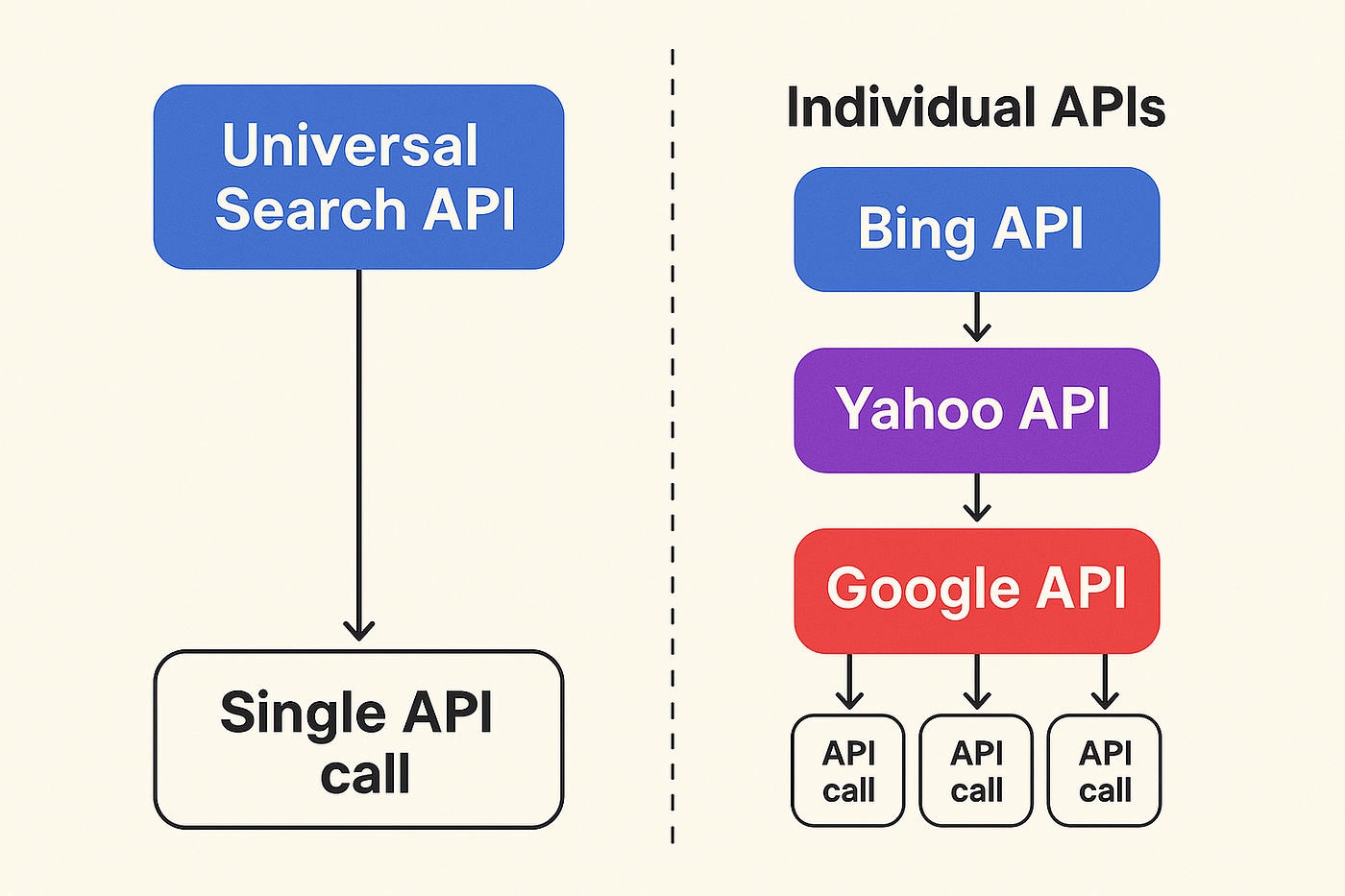
- LLMs typically rely on static databases, but integrating the Universal Search API enables them to access real-time data at lightning speed.
- You don’t have to integrate multiple APIs for scraping data from different search engines.
- Deduplication is critical when assembling datasets. This API saves you hours by ensuring no repeated links clutter your results.
Here’s a quick demo on Universal Search API. ⬇️
This code builds a very simple text generator using a Markov chain. First, it takes your collected snippets (the corpus) and learns which words tend to follow which. It does this by looking at pairs of words (like “Russia Ukraine”) and recording what word usually comes next (for example, “war”). The result is a dictionary where each pair of words points to a list of possible continuations.
Then, when you want to generate new text, the program picks a random starting pair and keeps adding words by checking what words are likely to follow the last two. By repeating this process, it creates a new sequence of words that looks similar to the original snippets but isn’t copied directly. Essentially, it’s a toy model that mimics writing style and context based on word transitions from your data.
Now let’s check the output of our code. You can run it with the command python llm.py.

So, we successfully built a lightweight LLM model without relying on multiple SERP APIs.


