First, make sure you have Python 3.x installed on your system. If not, you can download it from the official Python website.
Next, create a free account on Scrapingdog. You can sign up for the trial pack, which includes 1,000 free credits to test our APIs and start experimenting right away.
Finally, create a folder by any name you like. I am naming the folder as tutorial. Inside this folder, create a Python file. This is where we will keep our Python code.
Inside the folder, tutorial, install requests and pandas library.
- requests — This will be used for making an HTTP connection with the Scrapingdog APIs.
- pandas — This will be used for storing the scraped data in a csv file.
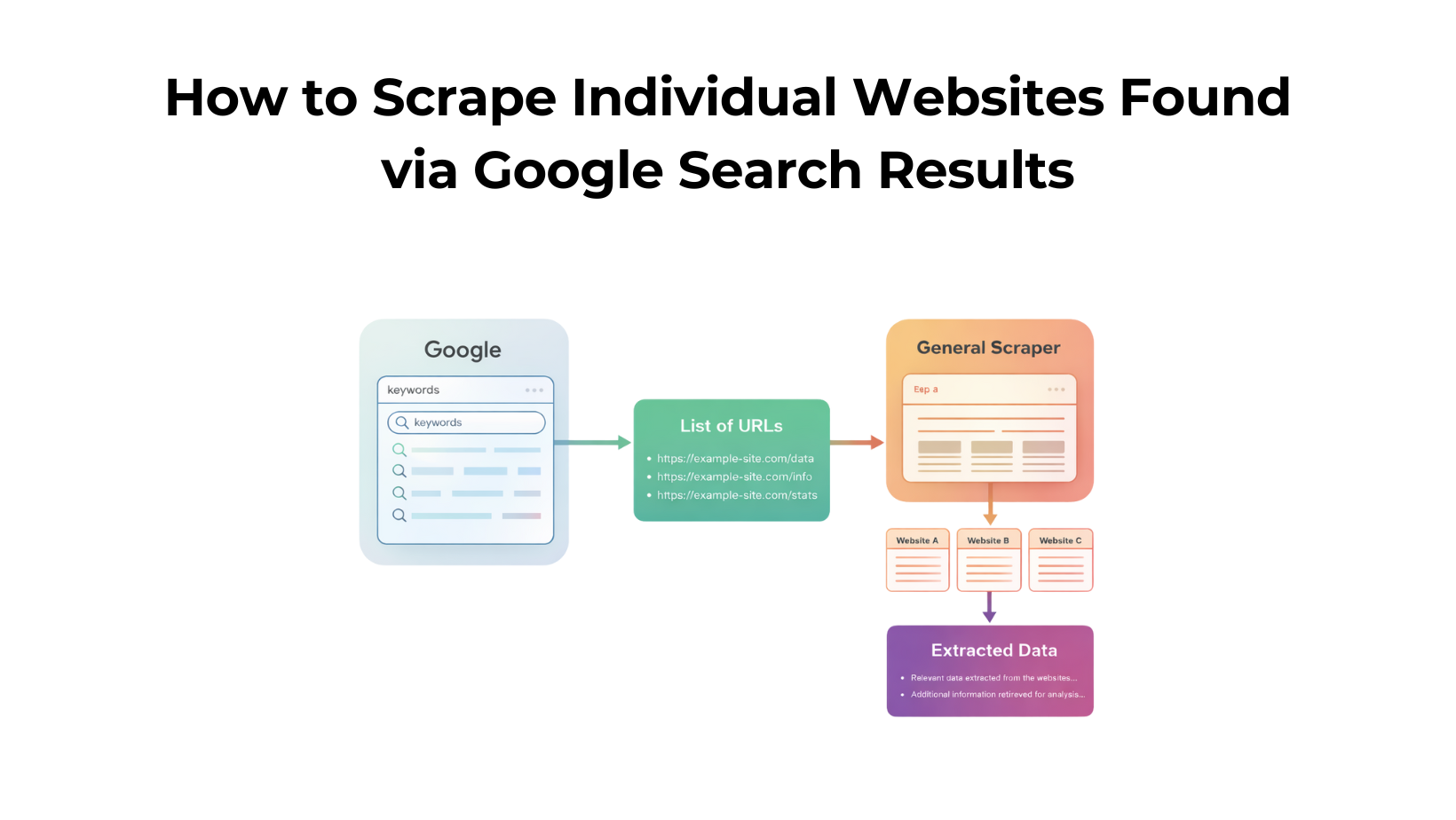
Process
- We will first scrape the SERP data using the Google Search API.
- Then we will use the general scraper to extract data from all the URLs received from serp data.
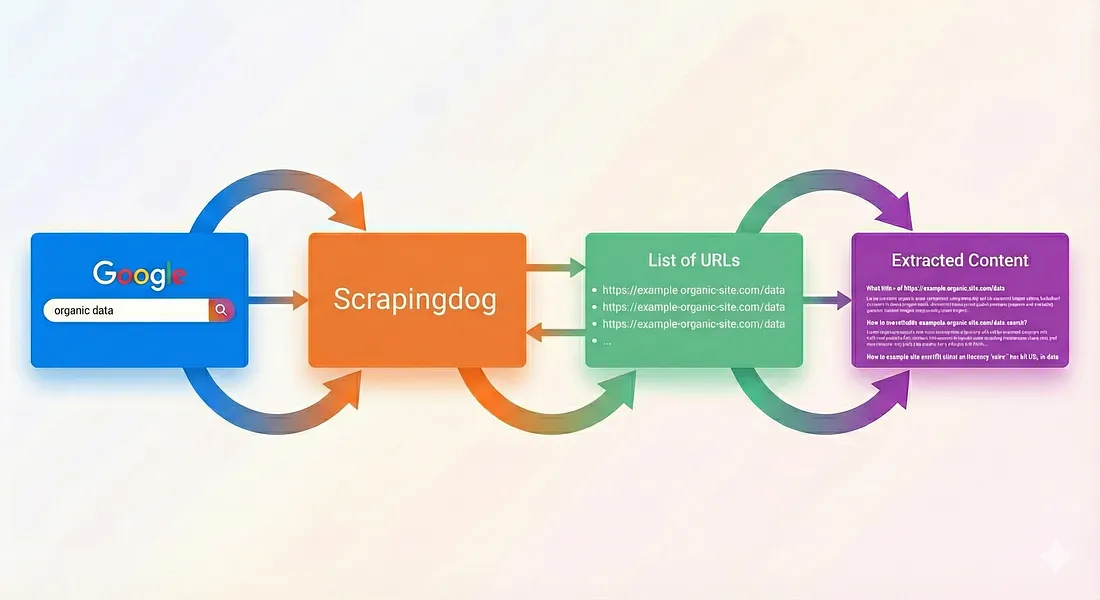
For this tutorial, we will scrape search results for the term football.

We will use Google Light Search API for this task because we only need the organic search results(Google Search Scraper API will provide you with ads, AI overview, etc).
The above code is pretty simple, but let me explain it to you step by step.
- Imports the requests library to make HTTP requests.
- Defines your API key and the Scrapingdog Google Search API endpoint.
- Creates query parameters for the API call (search term, country, language, etc.).
- Sends a GET request to Scrapingdog’s API with those parameters.
- Checks the response status — if it’s 200 (success), it converts the JSON response into a Python dictionary.
- Prints the search results if successful; otherwise, prints an error message with the status code.
Once you run this code, you will get a beautiful JSON array. In this response, you will find an array organic_results that will have all the links we need for the data extraction process in the next step.
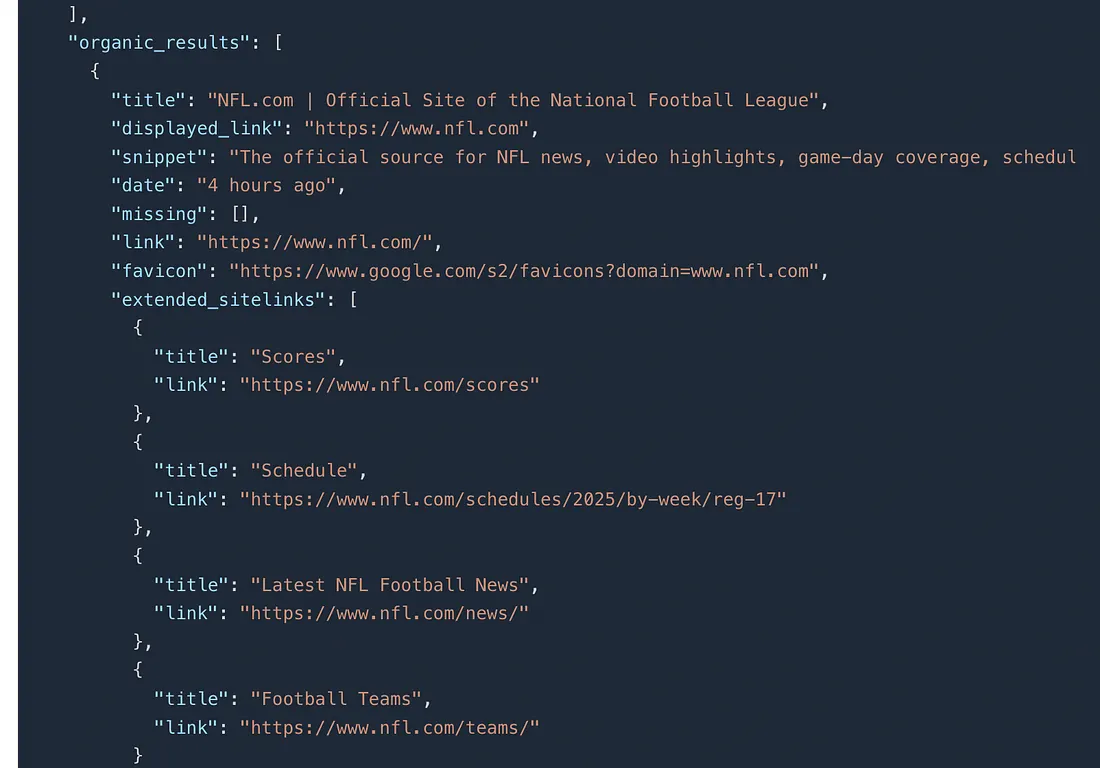
Now, let’s parse this JSON even further to collect all these links in a separate list.
In the above code, we are using for loop to iterate over all the organic search results we got. Finally, we are storing the links in a list called links.
Once you run this code, you will get this array printed on the console.



