
Google Jobs API
With Google Jobs API, you can easily extract job data like company name, title, location, apply link, and more from the Google job board. This is perfect for building job boards and analyzing the job market.
- 30-day free trial
- No credit card required
- 1000 credits free
- 30-day free trial
- No credit card required
- 1000 credits free

Features of our Google Job Search API
Real-time Job Data
Our Google Jobs API provides instant access to live job postings directly from Google, ensuring you always work with the most current listings.
Targeted Job Searches
Precisely filter job searches by location, vacancy, job type, salary & many more data points, empowering your users to find exactly what they’re looking for without hassle.
Seamless Integration
With easy-to-use endpoints and clear documentation, our Google Jobs scraper API integrates smoothly into your existing platforms or apps, saving you time and resources.
See how our API for Google Jobs gives the output data
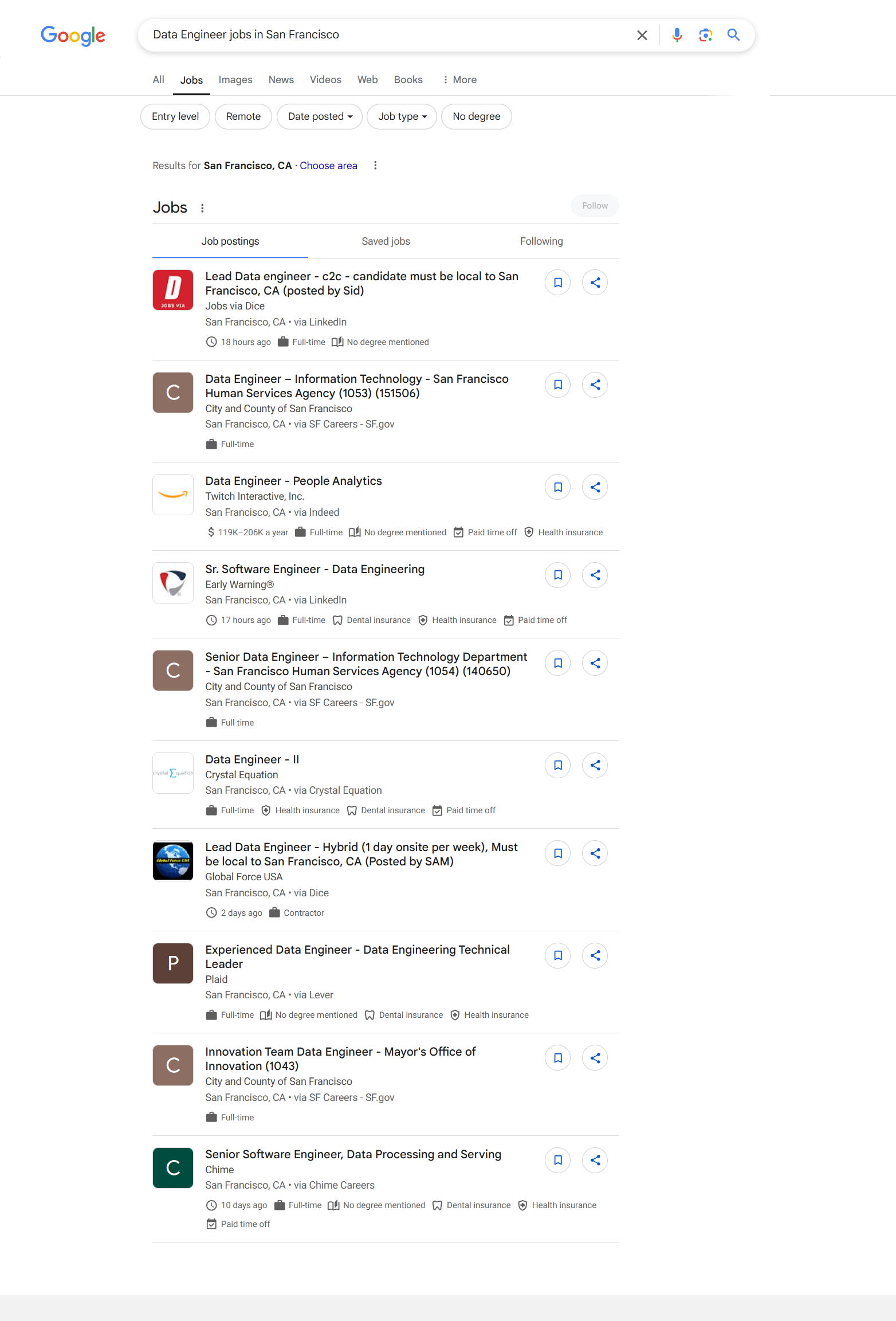
> curl "https://api.scrapingdog.com/google?api_key=5eaa61a6e562fc52fe763tr516e4653&query=new york&results=10&country=us&page=0"{
"jobs_results": [
{
"title": "Lead Data engineer - c2c - candidate must be local to San Francisco, CA (posted by Sid)",
"company_name": "Jobs via Dice",
"location": "San Francisco, CA",
"via": "LinkedIn",
"share_link": "https://www.google.com/search?ibp=htl;jobs&q=Data+Engineer+jobs+in+San+Francisco&htidocid=A8f6AiYanEssXLwVAAAAAA%3D%3D&hl=en-US&shndl=37&shmd=H4sIAAAAAAAA_2WOMU7DQBBFlTZHSPVFRVCwUaQ0oUKJQELpcoBodnZkL1rPWJ4BhWNyI5w6zev--2_5t1jqSSjjSEEQ7YqKTHgGb_lG0lwyhWD49kASVGOqCMOZFO8TKRdn2-DwhsfRPCQj_eJc8nqef1qCC03cwxQfZl2V1WsfMfq-bd1r03lQFG7YhtZUkl3bL0t-w8V7mmSs8_tlu3u5NqN2Tw-z0vFTCMfCgqL3Hf-Hk9FX1AAAAA&shmds=v1_AQbUm97BcAbJyBE3H5t6cwXZXmzv3OO__xK7I_C0p305-zRb8Q&source=sh/x/job/uv/m5/1#fpstate=tldetail&htivrt=jobs&htidocid=A8f6AiYanEssXLwVAAAAAA%3D%3D&htiq=Data+Engineer+jobs+in+San+Francisco",
"thumbnail": "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcR9CC1NlnLA7sshF1s1dqKvk8U495jsMwImnyPP&s=0",
"detected_extensions": {},
"description": "Dice is the leading career destination for tech experts at every stage of their careers. Our client, Global Force USA, is seeking the following. Apply via Dice today!\n\nRole: Lead Data Engineer c2c\n\nDuration: Long Term contract\n\nLocation: San Francisco, CA\n\nRequired Skills\n• Python and PySpark. Kafka and Kafka streams. MySQL and MySQL Heat. Azure Delta Lake. ETL processes. Kafka integrations using Spring Boot Java. Data streaming with Spark.\n\nAdditional Skills\n• Experience with Delta Lake on Azure Tableau or similar data visualization tools Unity Catalog in Databricks Airflow for pipeline management\n\nResponsibilities\n\nDevelopment Tasks:\n• Collect metrics based on user interactions.\n• Visualize data for business teams.\n• Develop and redesign data pipelines using Kafka streams.\n• Implement solutions using Spring Boot Java and Databricks Spark streaming.\n\nLeadership Duties:\n• Lead the measurement processes from requirements gathering to production delivery.\n• Collaborate with other team leads, business partners, and product managers.\n• Balance between hands-on engineering (50%) and team leadership (50%).\n\nCollaboration Structure:\n• Onsite: Lead role (this resource)\n• Nearshore: Senior developer.\n• Offshore: Data engineer role.\n\nLead Data Engineer - Job Description\n\nRequired Skills & Experience:\n• Hands-on code mindset with deep understanding in technologies / skillset and an ability to understand larger picture.\n• Sound knowledge to understand Architectural Patterns, best practices and Non-Functional Requirements\n• Overall, 8-10 years of experience in heavy volume data processing, data platform, data lake, big data, data warehouse, or equivalent.\n• 5+ years of experience with strong proficiency in Python and Spark (must-have).\n• 3+ years of hands-on experience in ETL workflows using Spark and Python.\n• 4+ years of experience with large-scale data loads, feature extraction, and data processing pipelines in different modes near real time, batch, realtime.\n• Solid understanding of data quality, data accuracy concepts and practices.\n• 3+ years of solid experience in building and deploying ML models in a production setup. Ability to quickly adapt and take care of data preprocessing, feature engineering, model engineering as needed.\n• Preferred: Experience working with Python deep learning libraries like any or more than one of these - PyTorch, Tensorflow, Keras or equivalent.\n• Preferred: Prior experience working with LLMs, transformers. Must be able to work through all phases of the model development as needed.\n• Experience integrating with various data stores, including:\n• SQL/NoSQL databases\n• In-memory stores like Redis\n• Data lakes (e.g., Delta Lake)\n• Experience with Kafka streams, producers & consumers.\n• Required: Experience with Databricks or similar data lake / data platform.\n• Required: Java and Spring Boot experience with respect to data processing - near real time, batch based.\n• Familiarity with notebook-based environments such as Jupyter Notebook.\n• Adaptability: Must be open to learning new technologies and approaches.\n• Initiative: Ability to take ownership of tasks, learn independently, and innovate.\n• With technology landscape changing rapidly, ability and willingness to learn new technologies as needed and produce results on job.\n\nPreferred Skills:\n• Ability to pivot from conventional approaches and develop creative solutions.",
"job_highlights": [
{
"title": "Qualifications",
"items": [
"Python and PySpark",
"Experience with Delta Lake on Azure Tableau or similar data visualization tools Unity Catalog in Databricks Airflow for pipeline management",
"Hands-on code mindset with deep understanding in technologies / skillset and an ability to understand larger picture",
"Sound knowledge to understand Architectural Patterns, best practices and Non-Functional Requirements",
"Overall, 8-10 years of experience in heavy volume data processing, data platform, data lake, big data, data warehouse, or equivalent",
"5+ years of experience with strong proficiency in Python and Spark (must-have)",
"3+ years of hands-on experience in ETL workflows using Spark and Python",
"4+ years of experience with large-scale data loads, feature extraction, and data processing pipelines in different modes near real time, batch, realtime",
"Solid understanding of data quality, data accuracy concepts and practices",
"3+ years of solid experience in building and deploying ML models in a production setup",
"Ability to quickly adapt and take care of data preprocessing, feature engineering, model engineering as needed",
"Must be able to work through all phases of the model development as needed",
"Experience integrating with various data stores, including:",
"SQL/NoSQL databases",
"In-memory stores like Redis",
"Data lakes (e.g., Delta Lake)",
"Experience with Kafka streams, producers & consumers",
"Required: Experience with Databricks or similar data lake / data platform",
"Required: Java and Spring Boot experience with respect to data processing - near real time, batch based",
"Familiarity with notebook-based environments such as Jupyter Notebook",
"Adaptability: Must be open to learning new technologies and approaches",
"Initiative: Ability to take ownership of tasks, learn independently, and innovate",
"With technology landscape changing rapidly, ability and willingness to learn new technologies as needed and produce results on job"
]
},
{
"title": "Benefits",
"items": null
},
{
"title": "Responsibilities",
"items": [
"Kafka integrations using Spring Boot Java",
"Collect metrics based on user interactions",
"Visualize data for business teams",
"Develop and redesign data pipelines using Kafka streams",
"Implement solutions using Spring Boot Java and Databricks Spark streaming",
"Lead the measurement processes from requirements gathering to production delivery",
"Collaborate with other team leads, business partners, and product managers",
"Balance between hands-on engineering (50%) and team leadership (50%)",
"Onsite: Lead role (this resource)",
"Offshore: Data engineer role"
]
}
],
"apply_options": [
{
"title": "LinkedIn",
"link": "https://www.linkedin.com/jobs/view/lead-data-engineer-c2c-candidate-must-be-local-to-san-francisco-ca-posted-by-sid-at-jobs-via-dice-4198748840?utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
},
{
"title": "Dice",
"link": "https://www.dice.com/job-detail/b6e7b0a8-fdbe-44fd-a490-0abcade5389c?utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
}
],
"job_id": "eyJqb2JfdGl0bGUiOiJMZWFkIERhdGEgZW5naW5lZXIgLSBjMmMgLSBjYW5kaWRhdGUgbXVzdCBiZSBsb2NhbCB0byBTYW4gRnJhbmNpc2NvLCBDQSAocG9zdGVkIGJ5IFNpZCkiLCJjb21wYW55X25hbWUiOiJKb2JzIHZpYSBEaWNlIiwiYWRkcmVzc19jaXR5IjoiU2FuIEZyYW5jaXNjbywgQ0EiLCJodGlkb2NpZCI6IkE4ZjZBaVlhbkVzc1hMd1ZBQUFBQUE9PSIsImhsIjoiZW4ifQ=="
},
...
],
}We Streamline Google Jobs Scraping for You
Comprehensive Job Market Insights
Gain a complete overview of job market trends by effortlessly accessing and analyzing millions of Google job postings, helping you make informed hiring decisions.
Competitive Analysis
Monitor and analyze job postings from competitors or industry leaders directly from Google Jobs, empowering your strategic decisions with data-backed insights.
Real-time Job Post Monitoring
Scrape live Google Jobs data to instantly track and respond to new job postings, changes, or removals, enabling proactive hiring and recruiting strategies.
Detailed Job Data Extraction
Extract detailed job information such as roles, salaries, locations, company details, and descriptions from Google Jobs, facilitating precise job matching and data-driven market research.
Use Cases of Scraping data from the Google Job Board
Competitor Hiring Analysis
Analyze the hiring patterns and job trends of your competitors by scraping their latest job postings, revealing insights into their strategic moves and expansion plans.
Academic Research
Collect extensive data from Google Jobs to support research in labor economics, employment trends, industry growth, and job market dynamics.
Employment Trend Forecasting
Detect and forecast emerging employment trends by regularly scraping Google Jobs, allowing proactive adjustment of recruitment or training strategies.
Job Market Reporting
Automate the collection of comprehensive job listings data for market reports, industry analyses, and informative content, streamlining your reporting processes.
Salary Benchmarking
Scraped salary information from job postings to establish accurate salary benchmarks within industries or geographic regions, supporting data-driven compensation strategies.
Regional Job Market Mapping
Map job availability across cities, regions, or countries by scraping geo-specific job listings from Google Jobs, aiding regional economic analysis and targeted workforce planning.
Testimonial
Transparent & Simple Pricing
LITE
$40/month
- 200000 Credits = 40000 Google Requests
- $1/1k Google Requests
- 5 Concurrency
- No Email Support
- No Team Management
STANDARD
$90/month
- 1000000 Credits = 200000 Google Requests
- $0.45/1k Google Requests
- 50 Concurrency
- Email Support
- No Team Management
PRO
$200/month
- 3000000 Credits = 600000 Google Requests
- $0.33/1k Google Requests
- 100 Concurrency
- Priority Email Support
- Team Management
Popular
PREMIUM
$350/month
- 6000000 Credits =1200000 Google Requests
- $0.29/1k Google Requests
- 150 Concurrency
- Priority Email Support
- Team Management
BUSINESS
$500/month
- 9000000 Credits = 1800000 Google Requests
- $0.27/1k Google Requests
- 200 Concurrency
- Priority Email Support
- Team Management
BUSINESS PLUS
$1000/month
- 19000000 Credits = 3800000 Google Requests
- $0.26/1k Google Requests
- 250 Concurrency
- Priority Email Support
- Team Management
BUSINESS PRO
$1500/month
- 29000000 Credits = 5800000 Google Requests
- $0.25/1k Google Requests
- 300 Concurrency
- Priority Email Support
- Team Management
CORPORATE
$2000/month
- 42000000 Credits = 8400000 Google Requests
- $0.23/1k Google Requests
- 350 Concurrency
- Priority Email Support
- Team Management
CORPORATE PLUS
$2500/month
- 55000000 Credits = 11000000 Google Requests
- $0.22/1k Google Requests
- 400 Concurrency
- Priority Email Support
- Team Management
CORPORATE PRO
$3000/month
- 65000000 Credits = 13000000 Google Requests
- $0.23/1k Google Requests
- 450 Concurrency
- Priority Email Support
- Team Management
ENTERPRISE STARTER
$4000/month
- 90000000 Credits = 18000000 Google Requests
- $0.22/1k Google Requests
- 500 Concurrency
- Priority Email Support
- Team Management
ENTERPRISE PLUS
$5000/month
- 120000000 Credits = 24000000 Google Requests
- $0.20/1k Google Requests
- 600 Concurrency
- Dedicated Support
- Team Management
ENTERPRISE PRO
$6000/month
- 150000000 Credits = 30000000 Google Requests
- $0.20/1k Google Requests
- 650 Concurrency
- Dedicated Support
- Team Management
GLOBAL STARTER
$7000/month
- 185000000 Credits = 37000000 Google Requests
- $0.18/1k Google Requests
- 700 Concurrency
- Dedicated Support
- Team Management
GLOBAL PLUS
$8000/month
- 220000000 Credits = 44000000 Google Requests
- $0.18/1k Google Requests
- 800 Concurrency
- Dedicated Support
- Team Management
GLOBAL PRO
$9000/month
- 255000000 Credits = 51000000 Google Requests
- $0.17/1k Google Requests
- 850 Concurrency
- Dedicated Support
- Team Management
GLOBAL ELITE
$10000/month
- 295000000 Credits = 59000000 Google Requests
- $0.16/1k Google Requests
- 900 Concurrency
- Dedicated Support
- Team Management
ULTRA STARTER
$12000/month
- 360000000 Credits = 72000000 Google Requests
- $0.16/1k Google Requests
- 1000 Concurrency
- Dedicated Support
- Team Management
ULTRA PLUS
$14000/month
- 430000000 Credits = 86000000 Google Requests
- $0.16/1k Google Requests
- 1200 Concurrency
- Dedicated Support
- Team Management
ULTRA PRO
$16000/month
- 500000000 Credits = 100000000 Google Requests
- $0.16/1k Google Requests
- 1300 Concurrency
- Dedicated Support
- Team Management
TITAN STARTER
$18000/month
- 580000000 Credits = 116000000 Google Requests
- $0.15/1k Google Requests
- 1400 Concurrency
- Dedicated Support
- Team Management
TITAN PLUS
$20000/month
- 660000000 Credits = 13200000 Google Requests
- $0.15/1k Google Requests
- 1500 Concurrency
- Dedicated Support
- Team Management
TITAN PRO
$22000/month
- 740000000 Credits = 14800000 Google Requests
- $0.14/1k Google Requests
- 1700 Concurrency
- Dedicated Support
- Team Management
TITAN ELITE
$24000/month
- 830000000 Credits = 166000000 Google Requests
- $0.14/1k Google Requests
- 1800 Concurrency
- Dedicated Support
- Team Management
NOVA STARTER
$26000/month
- 920000000 Credits = 184000000 Google Requests
- $0.14/1k Google Requests
- 1900 Concurrency
- Dedicated Support
- Team Management
NOVA PLUS
$28000/month
- 1010000000 Credits = 202000000 Google Requests
- $0.13/1k Google Requests
- 2000 Concurrency
- Dedicated Support
- Team Management
NOVA PRO
$30000/month
- 1100000000 Credits = 220,000,000 Google Requests
- $0.13/1k Google Requests
- 2200 Concurrency
- Dedicated Support
- Team Management
LITE
$33/month
- 200000 Credits = 40000 Google Requests
- $0.825/1k Google Requests
- 5 Concurrency
- No Email Support
- No Team Management
STANDARD
$75/month
- 1000000 Credits = 200000 Google Requests
- $0.375/1k Google Requests
- 50 Concurrency
- Priority Email Support
- No Team Management
PRO
$166/month
- 3000000 Credits = 600000 Google Requests
- $0.27/1k Google Requests
- 100 Concurrency
- Priority Email Support
- Team Management
Popular
PREMIUM
$291/month
- 6000000 Credits =1200000 Google Requests
- $0.24/1k Google Requests
- 150 Concurrency
- Priority Email Support
- Team Management
BUSINESS
$416/month
- 9000000 Credits = 1800000 Google Requests
- $0.233/1k Google Requests
- 200 Concurrency
- Access To All APIs
- Geotargeting
- Priority Email Support
- Team Management
BUSINESS PLUS
$833.33/month
- 19000000 Requests Credits
- 250 Concurrency
- Access To All APIs
- Geotargeting
- Priority Email Support
- Team Management
BUSINESS PRO
$1250/month
- 29000000 Requests Credits
- 300 Concurrency
- Access To All APIs
- Geotargeting
- Priority Email Support
- Team Management
CORPORATE
$1666/month
- 42000000 Requests Credits
- 350 Concurrency
- Access To All APIs
- Geotargeting
- Priority Email Support
- Team Management
CORPORATE PLUS
$2083/month
- 55000000 Requests Credits
- 400 Concurrency
- Access To All APIs
- Geotargeting
- Priority Email Support
- Team Management
CORPORATE PRO
$2500/month
- 65000000 Requests Credits
- 450 Concurrency
- Access To All APIs
- Geotargeting
- Priority Email Support
- Team Management
ENTERPRISE STARTER
$3333/month
- 90000000 Requests Credits
- 500 Concurrency
- Access To All APIs
- Geotargeting
- Priority Email Support
- Team Management
ENTERPRISE PLUS
$4166/month
- 120000000 Requests Credits
- 600 Concurrency
- Access To All APIs
- Geotargeting
- Dedicated Support
- Team Management
ENTERPRISE PRO
$5000/month
- 150000000 Requests Credits
- 650 Concurrency
- Access To All APIs
- Geotargeting
- Dedicated Support
- Team Management
GLOBAL STARTER
$5833/month
- 185000000 Requests Credits
- 700 Concurrency
- Access To All APIs
- Geotargeting
- Dedicated Support
- Team Management
GLOBAL PLUS
$6666/month
- 220000000 Requests Credits
- 800 Concurrency
- Access To All APIs
- Geotargeting
- Dedicated Support
- Team Management
GLOBAL PRO
$7500/month
- 255000000 Requests Credits
- 850 Concurrency
- Access To All APIs
- Geotargeting
- Dedicated Support
- Team Management
GLOBAL ELITE
$8333/month
- 295000000 Requests Credits
- 900 Concurrency
- Access To All APIs
- Geotargeting
- Dedicated Support
- Team Management
ULTRA STARTER
$10000/month
- 360000000 Requests Credits
- 1000 Concurrency
- Access To All APIs
- Geotargeting
- Dedicated Support
- Team Management
ULTRA PLUS
$11666/month
- 430000000 Requests Credits
- 1200 Concurrency
- Access To All APIs
- Geotargeting
- Dedicated Support
- Team Management
ULTRA PRO
$13333/month
- 500000000 Requests Credits
- 1300 Concurrency
- Access To All APIs
- Geotargeting
- Dedicated Support
- Team Management
TITAN STARTER
$15000/month
- 580000000 Requests Credits
- 1400 Concurrency
- Access To All APIs
- Geotargeting
- Dedicated Support
- Team Management
TITAN PLUS
$16666/month
- 660000000 Requests Credits
- 1500 Concurrency
- Access To All APIs
- Geotargeting
- Dedicated Support
- Team Management
TITAN PRO
$18333/month
- 740000000 Requests Credits
- 1700 Concurrency
- Access To All APIs
- Geotargeting
- Dedicated Support
- Team Management
TITAN ELITE
$20000/month
- 830000000 Requests Credits
- 1800 Concurrency
- Access To All APIs
- Geotargeting
- Dedicated Support
- Team Management
NOVA STARTER
$21666/month
- 920000000 Requests Credits
- 1900 Concurrency
- Access To All APIs
- Geotargeting
- Dedicated Support
- Team Management
NOVA PLUS
$23333/month
- 1010000000 Requests Credits
- 2000 Concurrency
- Access To All APIs
- Geotargeting
- Dedicated Support
- Team Management
NOVA PRO
$25000/month
- 1100000000 Requests Credits
- 2200 Concurrency
- Access To All APIs
- Geotargeting
- Dedicated Support
- Team Management
Need a bigger plan?
Frequently Asked Questions
Yes, the API has a rate limit depending on your chosen subscription plan. For detailed information on request limits and how to manage them efficiently, please refer to documentation or message us on live chat.
Yes, other then the data from search results, we have dedicated APIs for Google Scholar, Google Images, Google Lens etc, You can check them out in the product section in the header section for more info.
Google officially shut down the Jobs API in 2021. You can use third-party providers like Scrapingdog Google Jobs API.
Each API request consumes a certain number of credits based on the dedicated API you’re using.
For example the Google Search API costs 5 credits per request. So, if you make one request to the Google Search API, it will deduct 5 credits from the available credits in your account. The number of credits required per request can vary depending on the specific API you’re using.
You can find more details about the credit usage for each API in the documentation.