TL;DR
- 2026: web-scraping market racing toward multi-billion ($2.2–3.5B); alt-data at $4.9B, +28% YoY.
- Dev stack: Python 69.6%; methods , proxies 39.1%, APIs 34.8%, cloud 26.1; BS4 / Crawlee / Selenium / Playwright common.
- AI: 30–40% faster extraction, up to 99.5% accuracy; adapts to layout changes.
- Priorities: freshness, geo-scale, compliance; Scrapingdog now offers an AI scraper.
Almost half of the internet will have bot traffic in 2026. Automated data collection has quietly become one of the engines of the modern internet.
And from real-time price tracking to powering AI models, web scraping is something that now powers critical workflows, showing businesses stay informed and remain competitive.
At Scrapingdog, we’ve seen this shift up close. What was once a niche practice for developers is now a strategic investment for companies of all sizes. The latest numbers show just how far the industry has come and where it’s headed next.
Here’s your snapshot of the 2026 web scraping landscape. Below this infographic, we will discuss each of them in detail.

A Market on the Rise
As the demand for data is growing, so is the need to ethically collect it. Businesses in e-commerce, finance, travel, and AI are now relying heavily on web scraping to gather competitive intelligence, monitor trends, and feed machine learning models.
Multiple independent market research firms have analysed the sector and reported consistent upward trends.
The figures vary by source due to differences in research scope, methodology, and market definitions, but the message is clear: web scraping is set for long-term, sustained expansion.
Below are the latest market size estimates and forecasts from leading research sources.

2024 Market Size: USD 703.6M
Forecast: USD 3.52B by 2037 (CAGR 13.2%)
Why it matters: This is one of the most conservative estimates, yet it still points to a 5× market expansion over the next decade. It underlines the steady and predictable nature of industry growth.
2024 Market Size: USD 718.9M
Forecast: USD 2.21B by 2033 (CAGR 13.3%)
Why it matters: This aligns closely with other mid-range forecasts and reflects confidence in web scraping’s adoption in mainstream enterprise workflows.
2024 Market Size: USD 1.01B
Forecast: USD 2.49B by 2032 (CAGR 16%)
Why it matters: This is a higher baseline estimate, suggesting that some analysts see the market as already crossing the USD 1B mark. It reflects the expanding range of use cases and the growing number of SaaS solutions offering scraping as a service.
Alternative Data Market Context
2023 Market Size: USD 4.9B
Annual Growth: 28%
Why it matters: Web scraping is a major feeder into the alternative data market, which powers hedge funds, analytics platforms, and AI systems. Understanding this broader market shows the indirect growth drivers for scraping services.
Key takeaway: Even at the lowest estimates, the web scraping software market is on track for double-digit annual growth, with multi-billion-dollar potential by the next decade. This consistent growth across multiple research firms is a strong indicator that investment in scraping technology is not just a short-term trend but a long-term business enabler.
How Developers Are Scraping in 2026
The tools, languages, and workflows used for web scraping have evolved significantly. Developer surveys reveal a clear shift away from ad-hoc scripts toward structured, API-driven, and cloud-based setups.
This change is driven by the need for scalability, accuracy, and reduced maintenance, allowing teams to focus more on analysis than on managing scraping infrastructure.
Usage of Scraping Methods

39.1% use proxy providers
Why it matters: Proxies are essential for location-specific data collection and for accessing content without being blocked. This reflects the importance of bypassing geo-restrictions and maintaining scraper uptime.
34.8% use web scraping APIs
Why it matters: Web Scraping APIs offer structured, ready-to-use data without the complexity of maintaining scrapers — signalling a move toward outsourcing scraping infrastructure for reliability.
26.1% use cloud-based scraping platforms
Why it matters: Cloud solutions allow scaling to millions of requests without local hardware limitations, enabling real-time or near-real-time scraping at scale.
Tech Stack Preferences
Python dominates with 69.6% adoption
Why it matters: Python’s rich scraping ecosystem (BeautifulSoup, Scrapy, Playwright) and its readability make it the go-to language for scraping projects, both for beginners and large-scale production setups.
Read More: Web Scraping in Python (Complete Guide)
Most-used libraries & frameworks:
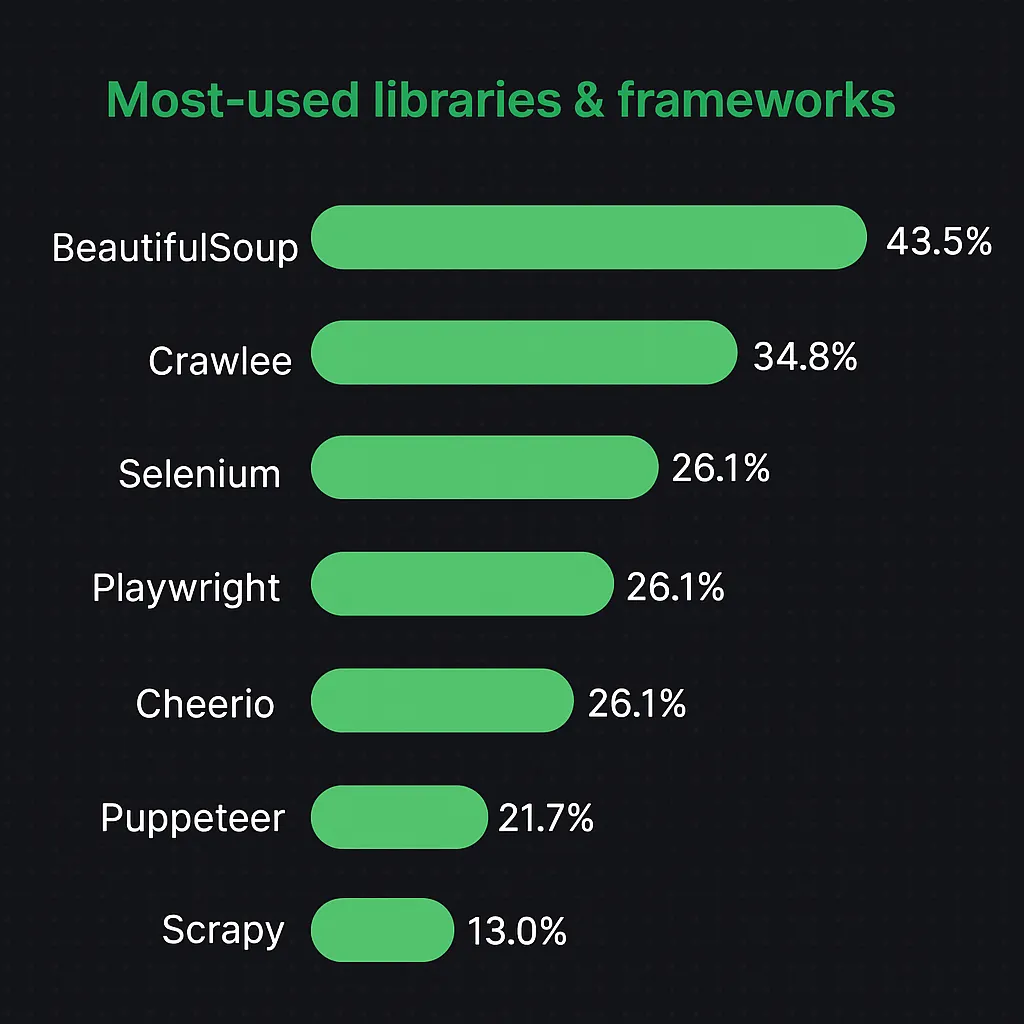
BeautifulSoup (43.5%) — simple, flexible HTML/XML parsing. (Web Scraping with BeutifulSoup)
Crawlee (34.8%) — robust framework for scalable crawlers.
Selenium (26.1%) — browser automation for dynamic content. (Web Scraping with Selenium)
Playwright (26.1%) — modern browser automation with multi-browser support.
Cheerio (26.1%) — fast HTML parser for Node.js.
Puppeteer (21.7%) — Chrome-based browser automation. (Web Scraping using Puppeteer)
Scrapy (13.0%) — a high-performance Python framework for large scraping projects. (Web Scraping with Scrapy)
Why it matters: This variety shows the mix of lightweight parsers for static sites and full browser automation tools for dynamic content, indicating that scraping strategies are highly project-specific.
Key takeaway: The scraping community is standardising on flexible, scalable, and automation-friendly workflows. Whether through APIs, proxies, or cloud infrastructure, the aim is the same: faster, more reliable, and more maintainable data collection.
AI is Reshaping Web Scraping
Artificial intelligence is changing how web scraping is performed, making it faster, more accurate, and more adaptable to complex site structures.
Using AI with traditional scraping methods, businesses can overcome challenges that previously required a lot of time.
Faster Data Extraction
Stat: AI-powered scraping delivers 30–40% faster data extraction times.
Why it matters: Speed is critical when working with time-sensitive datasets like price tracking, news aggregation, or stock data. Faster extractions mean fresher insights and quicker decision-making.
Higher Accuracy on Complex Sites
Stat: AI-based scrapers can achieve accuracy rates of up to 99.5% when handling dynamic, JavaScript-heavy websites.
Why it matters: Many modern websites use client-side rendering and interactive elements. AI improves element detection, reducing errors and the need for post-processing.
Intelligent Adaptability
Finding: AI can dynamically adjust to layout changes and unexpected variations in site structure.
Why it matters: Traditional scrapers often break when page layouts change. AI-enabled scrapers can detect and adapt to these changes automatically, reducing downtime and maintenance costs.
Key takeaway: AI is turning web scraping from a reactive, maintenance-heavy process into a proactive, self-optimising operation, allowing teams to scale data collection without constant manual intervention.
Scrapingdog has recently launched an AI web scraper that you can use by simply prompting & get output data in any format you desire.
Businesses Are Investing in Responsible, Scalable Data Collection
As web scraping becomes more central to business intelligence, companies are prioritising reliability, compliance, and scalability in their data collection strategies. The focus is shifting from “just getting the data” to getting the right data, at the right time, in the right way.
Emphasis on Freshness and Accuracy
Finding: Organisations are prioritising systems that deliver up-to-date, high-quality datasets.
Why it matters: Fresh data ensures competitive analyses, product monitoring, and AI model training remain relevant and effective. Stale data can lead to wrong business decisions and missed opportunities.
Scaling Through Global Infrastructure
Finding: Businesses are investing in infrastructure that can collect data from multiple geographies simultaneously.
Why it matters: Geo-targeted data is essential for market-specific insights, competitive pricing, and localised trend analysis. Without this capability, businesses risk missing out on region-specific opportunities.
Key takeaway: Data collection is evolving into a fully managed, scalable operation where freshness, accuracy, and compliance are just as important as speed and volume.
Companies that invest in these capabilities now will have a competitive advantage in the data-driven economy.
Final Thoughts
The numbers clearly show a growing adoption of automated scraping tools, Python’s dominance in tech stacks, and a shift towards frameworks that balance scalability with compliance.
As industries become increasingly data-driven, the ability to collect and process information efficiently will separate leaders from followers.
Organisations that adapt quickly, invest in smarter tools, refine their data strategies, and maintain ethical standards will be best positioned to thrive in coming future.