After signup on Scrapingdog you will be redirected to your dashboard. You will find a Baidu Search API over there.
Once you click on it, you will see a scraper where you just need to pass a sample query, and it will pull the data and return it to you in neat JSON format.
For this tutorial, we will pass the query as web scraping. After passing the query you will get a ready Python code; you just have to copy that and paste it in your Python file.
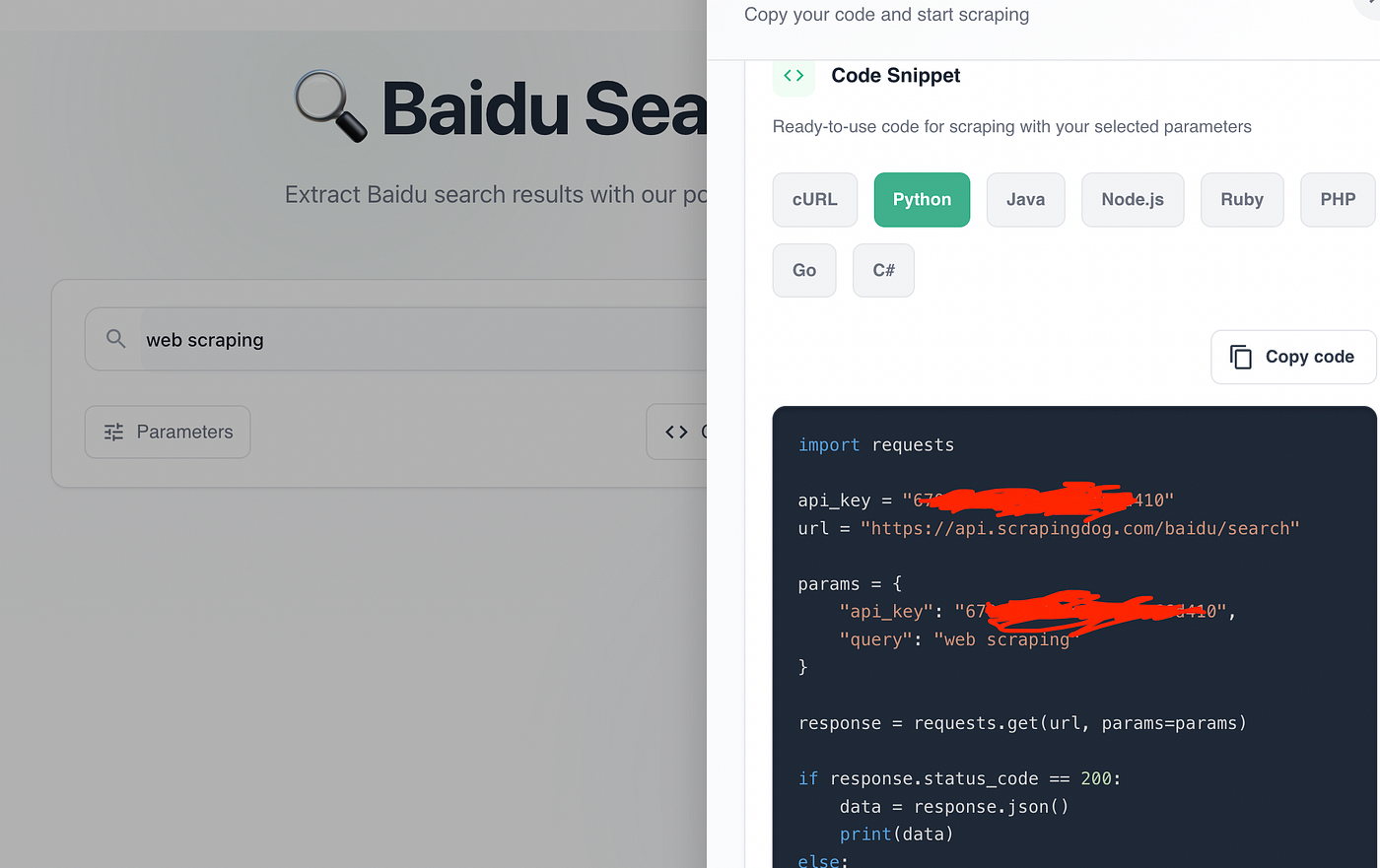
Let me explain this code step-by-step.
- First we have imported the
requestslibrary. This will be used for making the HTTP connection with the host website. - Then we are storing the API key and the Scrapingdog’s Baidu Search API URL.
- Then we are making the GET request with the help of
requestslibrary. - If the request is successful (status 200), it prints the search results.
- If it fails, it prints the error status code.
Once you run the code you will get this parsed JSON data.
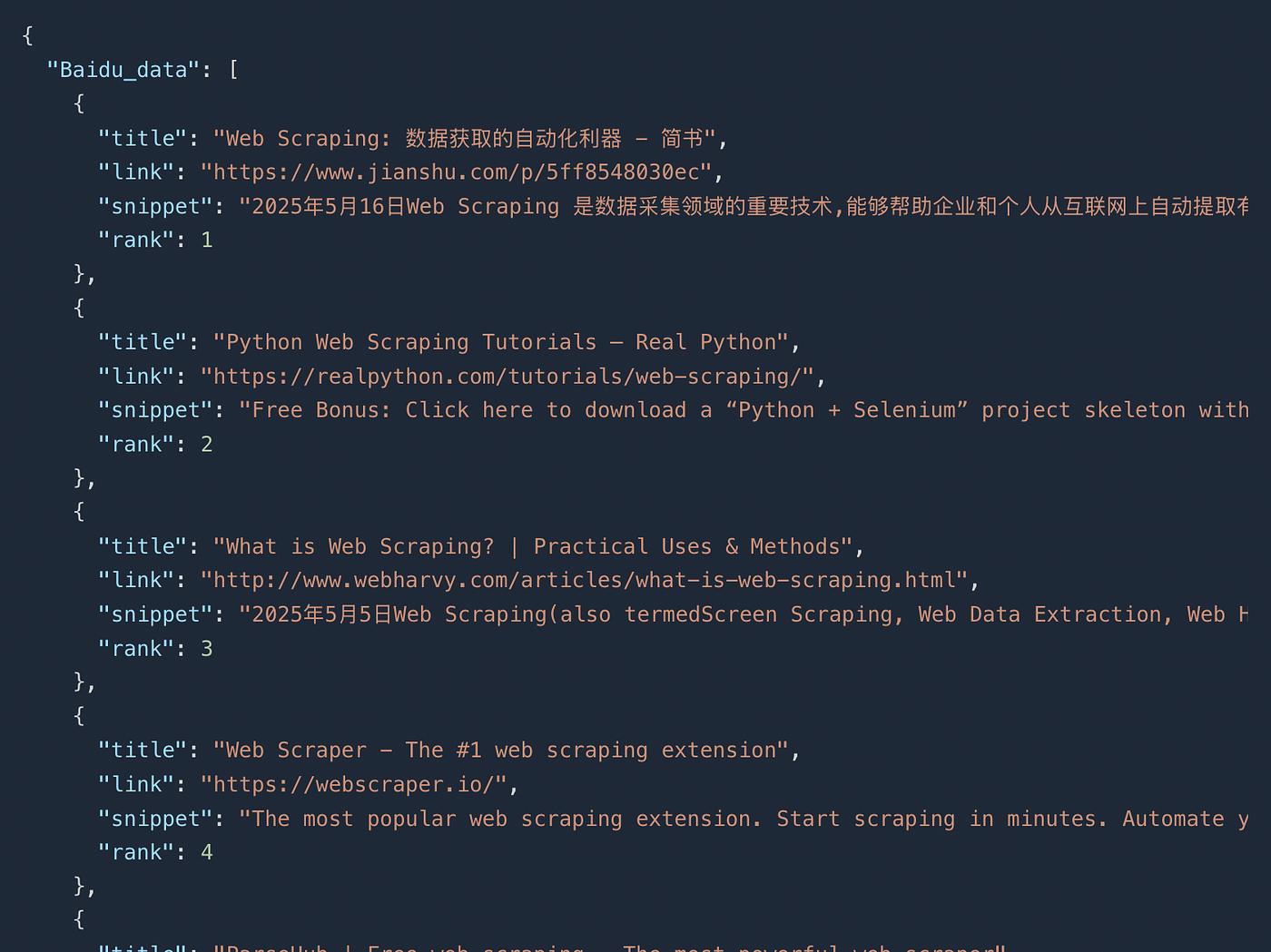
In this JSON response you will find the title, link, snippet and rank of the result.


