TL;DR
- Python tutorial: scrape Bing results with
Requests+BeautifulSoup(title, link, snippet, position). - Pagination: increase the first query param by 10 to walk pages; example loops through 10 pages.
- Complete working script provided.
- For scale you’ll face blocks — use rotating proxies / headers or Scrapingdog’s Bing Search API.
Bing is a great search engine; it beats Google in specific areas like image Search. I prefer Yandex or Bing when making an image search.
Generally, search engines are scraped to analyze fresh market trends, sentiment analysis, SEO, keyword tracking, or train LLMs, etc.
In this post, we are going to scrape search results from Bing. Once we have managed to scrape the first page, we will add a pagination system to it so that we can scrape all the pages Bing has over a keyword.
We are going to use Python for this tutorial, and I am assuming that you have already installed Python on your machine.
Why use Python to Scrape Search Results from Bing?
Python is a simple programming language that is also flexible and easy to understand even if you are a beginner. The Python community is too big and it helps when you face any error while coding.
Many forums like StackOverflow, GitHub, etc already have the answers to the errors that you might face while coding when you scrape Bing search results.
You can do countless things with Python, I even have made one tutorial on web scraping with Python in which I have covered all the libraries we can use.
Let's Start Scraping Bing
I have divided this into two sections. In the first section, we are going to scrape the first page, and then in the next section, we will scale our code to scrape all the pages by adding page numbers.
In the end, you will have a script that can scrape complete Bing search results for any keyword.
Let’s begin!
First part
We will create a folder and install all the libraries we might need during the course of this tutorial. Also, our target URL will be this Bing page.
For now, we will install two libraries
- Requests will help us to make an HTTP connection with Bing.
- BeautifulSoup will help us to create an HTML tree for smooth data extraction.
>> mkdir bing
>> pip install requests
>> pip install beautifulsoup4
Inside this folder, you can create a Python file where we will write our code.
- Title
- Link
- Description
- Position

import requests
from bs4 import BeautifulSoup
l=[]
o={}
target_url="https://www.bing.com/search?q=sydney&rdr=1"
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36"}
resp=requests.get(target_url,headers=headers)
Here we have imported the libraries we just installed and then made an HTTP GET request to the target URL. Now, we are going to use BS4 to create a tree for data extraction.
This can also be done through Xpath but for now, we are using BS4.
soup = BeautifulSoup(resp.text, 'html.parser')
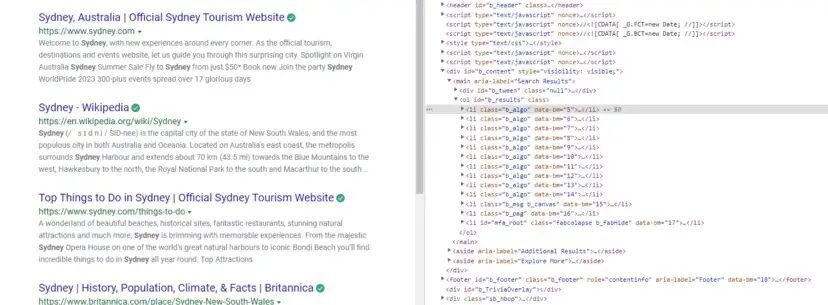
completeData = soup.find_all("li",{"class":"b_algo"})
In our soup variable, a complete HTML tree is stored through which we will extract our data of interest. completeData variable stores all the elements that we are going to scrape.
You can find it by inspecting it.
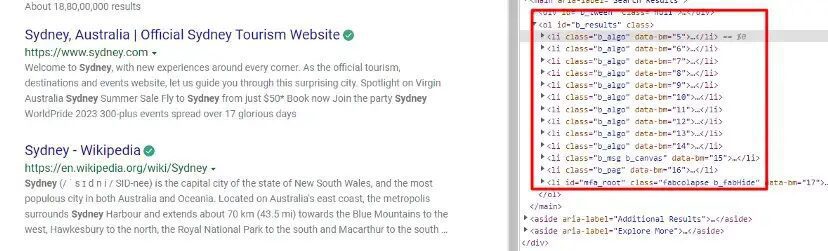
Let’s find out the location of each of these elements and extract them.
Scraping Title from Bing Search Result Page

o["Title"]=completeData[i].find("a").text
Scraping URLs from Bing Search Result Page
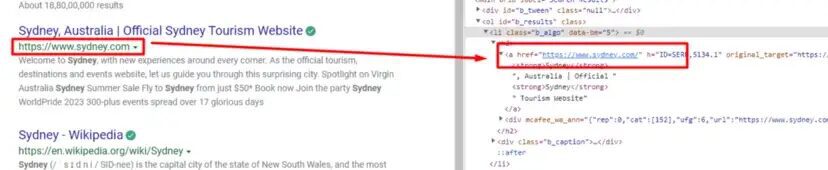
The description is stored under div tag with class b_caption.
o["Description"]=completeData[i].find("div",{"class":"b_caption"}).text
Let’s combine all this in a for loop and store all the data in the l array.
for i in range(0, len(completeData)):
o["Title"]=completeData[i].find("a").text
o["link"]=completeData[i].find("a").get("href")
o["Description"]=completeData[i].find("div",
{"class":"b_caption"}).text
o["Position"]=i+1
l.append(o)
o={}
print(l)

We have managed to scrape the first page. Now, let’s focus on scaling this code so that we can scrape all the pages for any given keyword.
Second Part
When you click on page two you will see a change in the URL. URL changes and a new query parameter is automatically added to it.
I page URL — https://www.bing.com/search?q=sydney&rdr=1&first=1
II page URL — https://www.bing.com/search?q=sydney&rdr=1&first=11
III page URL — https://www.bing.com/search?q=sydney&rdr=1&first=21
This indicates that the value of “first parameter” increases by 10 whenever you change the page. This observation will help us to change the URL pattern within the loop.
We will use a for loop which will increase the value by 10 every time it runs.
for i in range(0, len(completeData)):
o["Title"]=completeData[i].find("a").text
o["link"]=completeData[i].find("a").get("href")
o["Description"]=completeData[i].find("div",
{"class":"b_caption"}).text
o["Position"]=i+1
l.append(o)
o={}
print(l)
Here we are changing the target_url value by changing the value of the first parameter as we talked about earlier. This will provide us with a new URL every time the loop runs and for this tutorial, we are restricting the total pages to ten only.

Just like this, you can get data for any keyword by just changing the URL.
Complete Code
The complete code for the second section will more or less look like this.
import requests
from bs4 import BeautifulSoup
l=[]
o={}
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0
Safari/537.36"}
for i in range(0,100,10):
target_url="https://www.bing.com/search?q=sydney&rdr=1&first=
{}".format(i+1)
print(target_url)
resp=requests.get(target_url,headers=headers)
soup = BeautifulSoup(resp.text, 'html.parser')
completeData = soup.find_all("li",{"class":"b_algo"})
for i in range(0, len(completeData)):
o["Title"]=completeData[i].find("a").text
o["link"]=completeData[i].find("a").get("href")
o["Description"]=completeData[i].find("div",
{"class":"b_caption"}).text
o["Position"]=i+1
l.append(o)
o={}
print(l)
How can you scrape Bing search results without getting blocked?
Bing is a search engine that has a very sophisticated IP/bot detection system. If you want to scrape Bing at scale then scraping it just like we did above will not work.
You will need rotating proxies, headers, etc. Scrapingdog now offers a dedicated Bing Search API.
Here’s a small video walkthrough on how you can use Scrapingdog’s Bing Search API ⬇️
Let’s understand how you can scrape Bing with Scrapingdog with the free pack. In the free pack, you get 1000 free API calls and can scrape 200 bing results. Each call costs you 5 credits.
Once you sign up you will get an API key on the dashboard. You can use the same code above but in place of the target_url use the Scrapingdog API.
import requests
api_key = "YOUR-API-KEY"
url = "https://api.scrapingdog.com/bing/search/"
params = {
"api_key": api_key,
"query": "what+is+api",
"cc" : "us"
}
response = requests.get(url, params=params)
if response.status_code == 200:
data = response.json()
print(data)
else:
print(f"Request failed with status code: {response.status_code}")
In the above code, just replace “YOUR-API-KEY” with your own key. Execute this code, and it will result in a beautiful JSON response.
{
"bing_data": [
{
"title": "What is an API? A Beginner's Guide to APIs - Postman",
"displayed_link": "https://www.postman.com › what-is-an-api",
"link": "https://www.postman.com/what-is-an-api/",
"snippet": "Learn what an API is, how it works, and why it is important for modern applications. Explore the history, types, benefits, and examples of APIs with Postman, an API platform.",
"rank": 1,
"images": []
},
{
"title": "API - Wikipedia",
"displayed_link": "https://en.wikipedia.org › wiki › API",
"link": "https://en.wikipedia.org/wiki/API",
"snippet": "An API is a connection or interface between computers or software programs that allows them to communicate and interact. Learn about the origin, purpose, …",
"rank": 2,
"extensions": [
{
"title": "",
"snippet": ""
}
],
"images": []
},
...
]
}
This will create a seamless data pipeline, which can help you create tools like
- Rank Tracker
- Backlink Analysis
- News prediction
- Market prediction
- Image detection
Here are Some Key Takeaways:
Bing search results include data like titles, URLs, descriptions, and ranking positions.
Scraping requires handling query parameters and pagination for multiple result pages.
Bing may apply rate limits and bot detection, making headers and proxies important.
Extracted SERP data can be used for SEO tracking, keyword research, and competitor analysis.
Structured output formats like JSON make Bing data easy to integrate into analytics tools.
Conclusion
In this tutorial, you learned to scrape the Bing search engine. You can make some changes like calculating the number of pages it serves on the keyword provided, and then adjusting the for loop accordingly. You can even customize this code to scrape images from Bing.
For large-scale scraping, you can use our dedicated Bing SERP API. We do have a dedicated API for scraping Google search results.
I hope you like this tutorial. Please feel free to ask us any scraping-related questions we will respond to as many questions as possible.
Note: Scrapingdog has recently launched an all-in-one search engine API.
This API gives filtered data from all major search engines (Google + Bing + Yahoo + Duckduckgo).
We are calling it Universal SERP API. The advantage of using this API is that it allows you to take data in one API call; you don’t need to filter out repetitive results, and it is economical.
Additional Resources
Here are a few additional resources that you may find helpful during your web scraping journey:
- Web Scraping Google Search Engine using Python
- How To Scrape Baidu Search Results using Python
- How to Scrape Google Local Results using Scrapingdog’s API
- How To Scrape Google Images with Python (Store Data in CSV)
- Web Scraping Google News with Python (Get Data in CSV)
- Web Scraping Google Search Results using Scrapingdog’s Native Integration in Spreadsheets
- Scrape Google AI Mode using Python
- How To Scrape Google Maps (Store Data in CSV)
- 10 Best Google SERP APIs Tested & Ranked
- 5 Best Web Scraping Tools Tested on Performance, Documentation & Scalability