Web Scraping has become very common nowadays days as the demand for data extraction has gone up in recent years.
Pick any industry and you will find one thing in common i.e. their need for more data to efficiently analyze.
However, getting the extracted data at scale can be a bit frustrating, as many websites worldwide use on-screen data protection software like Cloudflare.
In this post, we will discuss the most common web scraping challenges you might face in your data extraction journey. Let’s understand them one by one.
CAPTCHAs
CAPTCHA is a Completely Automated Public Turing Test to Tell Computers and Humans Apart. Captchas are the most common kind of protection used by many websites around the world.
If an on-screen protection software thinks the incoming request is unusual then it will throw a captcha to test whether the incoming request is from a human or a robot. Once confirmed it will redirect the user to the main website.
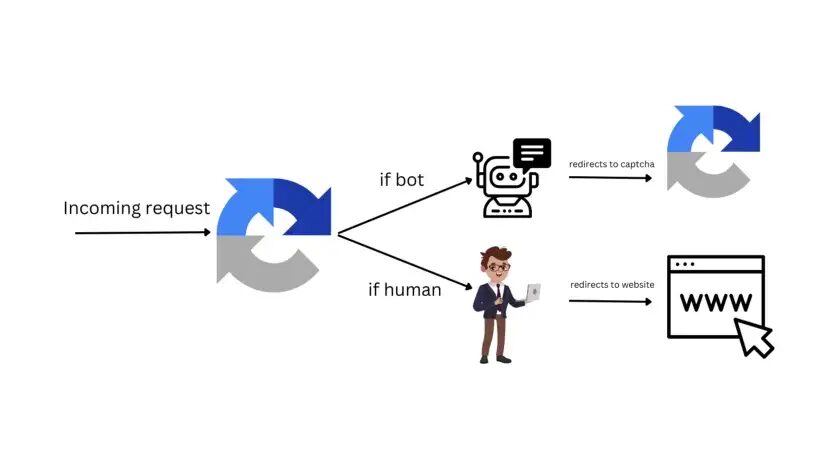
It is one of the major challenges of web scraping when extracting data from the web. This is a kind of test that a computer should not be able to pass but it should be able to grade. It is kind of a paradoxical idea.
There are multiple captcha-solving software in the market that can be used for solving captchas while scraping but they will slow down the scraping process and the cost of scraping per page will also go up drastically.
The only solution to this problem is to use proper headers along with high-quality residential proxies. This combination might help you bypass any kind of on-site protection. Residential proxies are high-authority IPs that come from a real device. The header object should contain proper User-Agent, referer, etc.
IP Blocking
IP blocking or IP bans are very common measures taken by website security software to prevent web scraping. Usually, this technique is used to prevent any kind of cyber attack or other illegal activities, ensuring DSPM compliance measures are upheld.
But along with this, IP bans can also block your bot which is collecting data through web scraping. There are mainly two kinds of IP bans.
- Sometimes website owners do not like bots collecting data from their websites without permission. They will block you after a certain number of requests.
- There are geo-restricted websites that only allow traffic from selected countries to visit their website.
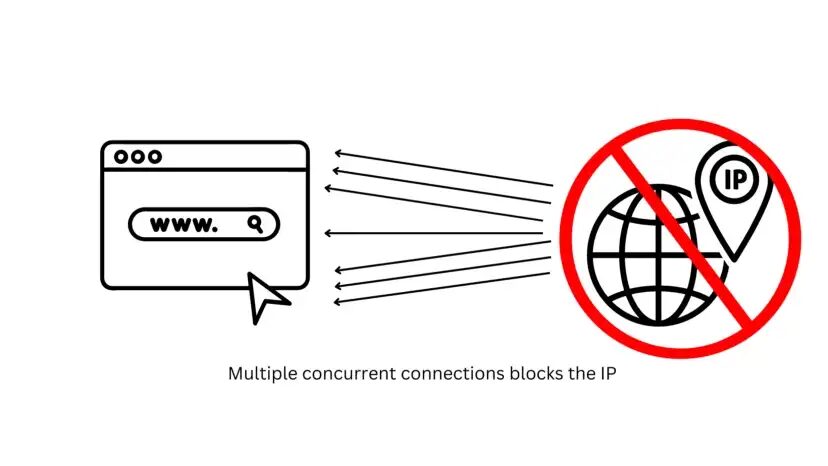
IP bans can also happen if you keep making connections to the website without any delay. This can overwhelm the host servers. Due to this, the website owner might limit your access to the website.
Another reason could be cookies.
Yes! this might sound strange but if your request headers do not contain cookies then you will get banned from the website. Websites like Instagram, Facebook, Twitter, etc. ban the IP if cookies are absent in the headers.
Dynamic Websites
Many websites use AJAX to load content on their website. These websites cannot be scraped with a normal GET request & are one of the important challenges to address when scraping. In AJAX architecture multiple API calls are made to load multiple components available on the website.
To scrape such websites you need a Chrome instance where you can load these websites and then scrape once they have loaded every component. You can use Selenium and Puppeteer to load websites on the cloud and then scrape it.
The difficult part is to scale the scraper. Let’s say you want to scrape websites like Myntra then you will require multiple instances to scrape multiple pages at a time.
This process is quite expensive and requires a lot of time to set up. Along with this, you need rotating proxies to prevent IP bans.
Change in Website Layout
In a year or so many popular websites change their website layout to make it more engaging. Once that is changed many tags and attributes also change.
And if you have created a data pipeline through that website then your pipeline will be blocked until you make appropriate changes at your end which further adds to one of the challenges.
Suppose you are scraping Amazon for cell phone prices and one day Amazon just changed the name of the element that holds that price tag. Eventually your scraper will also stop responding with correct information.
To avoid such a mishap, you can create a cron job that can run every 24 hours just to check if the layout is the same or different. If something changes you can shoot an alert email to yourself and after that, you can make the changes you need to keep the pipeline intact.
Even a minor change in the website layout will block your scraper from returning appropriate information.
Honeypot Traps
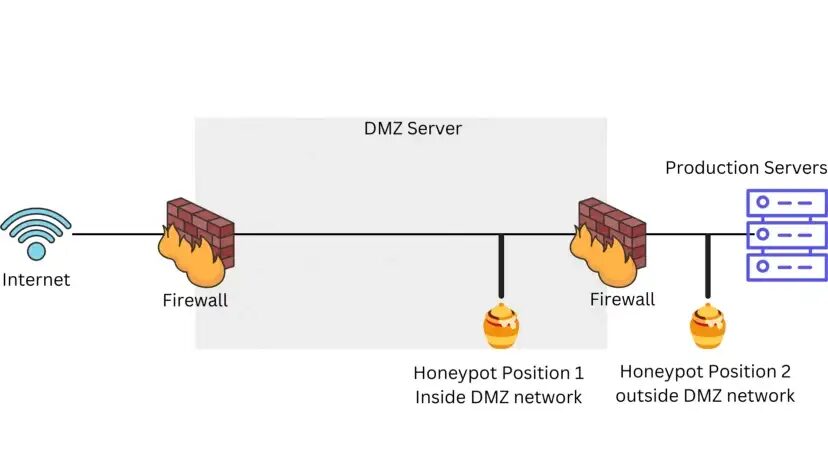
There are mainly two kinds of honeypot traps:
1. Research Honeypot Traps: close analysis of bot activity.
2. Production Honeypot Traps: It deflects intruders away from the real network.
Honeypot traps can be found in the form of a link that is only visible to bots but not humans. Once a bot falls into the trap, it starts gathering valuable information (IP address, Mac address, etc.). This information is then used to block any kind of hack or scraping.
Sometimes honeypot traps use the deflection principle by diverting the attacker’s attention to less valuable information.
The placement of these traps varies depending on their sophistication. It can be placed inside the network’s DMZ or outside the external firewall to detect attempts to enter the internal network. No matter the placement it will always have some degree of isolation from the production environment.
Data Cleaning
Web scraping will provide you with raw data. You have to parse out the data you need from the raw HTML.
Libraries like BeautifulSoup in Python, and Cheerio in Nodejs can help you clean the data and extract the data you are looking for.
One of the primary tasks in data cleaning is addressing missing data. Missing values can be problematic as they lead to gaps in the dataset, potentially introducing bias and errors in analytical results.
Data cleaning techniques often involve strategies like imputation, where missing values are replaced with estimated or derived values or the removal of records with significant data gaps.
Duplicate records are another common issue that data cleaning tackles. Duplicate entries skew statistical analyses and can misrepresent the underlying patterns in the data.
Data cleaning identifies and removes these duplicates, ensuring that each record is unique and contributes meaningfully to the analysis.
Additionally, data cleaning may involve identifying and handling outliers — data points that significantly deviate from the majority of the dataset. Outliers can distort statistical summaries and may require correction or removal to maintain the data’s integrity.
Authentication
Handling authentication in web scraping involves the process of providing credentials or cookies to access protected or restricted web resources.
Authentication is crucial when scraping websites that require users to log in or when accessing APIs that require API keys or tokens for authorization. There are several methods to handle authentication in web scraping.
One common approach is to include authentication details in your HTTP requests. For instance, if you’re scraping a website that uses basic authentication, you can include your username and password in the request’s headers.
Read More: How to send HTTP header using cURL?
Similarly, when accessing an API that requires an API key or token, you should include that key or token in the request headers. This way, the web server or API provider can verify your identity and grant you access to the requested data.
It’s essential to handle authentication securely, store credentials in a safe manner, and be cautious when sharing sensitive information in code or scripts.
How Scrapingdog Helps To Overcome These Web Scraping Challenges
We shared some of the challenges that pertain while you scrape the web. There can be many more real-world challenges when you do it practically.
We can overcome all these challenges by changing the scraping pattern. But if you want to scrape a large volume of pages then going with an API would give you a blockage-free data pipeline.
We at Scrapingdog offer an API for the same. You can test & spin the API for free first 1000 credits. Sign up from here!!
We will keep updating this article in the future with more web scraping challenges.
Happy Scraping👋
Additional Resources
- How To Use Cloudscraper using Python
- How To Bypass Amazon Captcha
- Cloudflare 1020 Error: How To Bypass It
- 499 Status Code & Solution To Avoid It
- Bypass 999 Response when Scraping LinkedIn Profiles
- Web Scraping vs Web Crawling: Know the Real Difference
- Difference between Data Extraction & Data Mining
- Web Scraping vs API: What’s the Similarity & Difference